API Docs¶
Modules and Packages¶
haggis |
haggis is the root package of the haggis library. |
haggis.args |
Utilities for processing command line arguments. |
haggis.configuration |
Recipes for handling different types of configuration files. |
haggis.ctypes_util |
Utilities and recipes for extending ctypes functionality. |
haggis.exceptions |
Utilities for implementing, raising and handling exceptions. |
haggis.files |
Routines for dealing with file types. |
haggis.files.csv |
Utilities for processing CSV files. |
haggis.files.docx |
Utilities for working with new-style MS Word documents, only available when the [docx] extra is installed. |
haggis.files.fits |
Utilities for working with FITS files, only available when the [scio] extra is installed. |
haggis.files.pdf |
Conversion utilities for PDF files to other formats. |
haggis.files.ps |
Conversion utilities for PostScript (PS, EPS) files to other formats. |
haggis.files.ui |
Utilities for interacting with the file system with an optional graphical user interface. |
haggis.files.xlsx |
Utilities for working with new-style MS Excel documents, only available when the [xlsx] extra is installed. |
haggis.files.xml |
Utilities for extending and configuring the Python XML framework. |
haggis.files.zip |
Utilities for working with zip archives. |
haggis.latex_util |
Utilities for processing bits of latex using matplotlib for rendering. |
haggis.load |
Custom module loading functionality for Python code, wrapped around portions of importlib. |
haggis.logs |
Utilities for extending and configuring the logging framework. |
haggis.mapping |
Recipes specifically for manipulating and emulating mappings, namespaces and the like. |
haggis.math |
Math utility functions that are otherwise uncategorized. |
haggis.mpl_util |
Utilities for handling MatPlotLib figures, only available when the [plot] extra is installed. |
haggis.npy_util |
Utilities for manipulating non-computational aspects of numpy arrays. |
haggis.numbers |
Various written-language related routines pertaining to numbers. |
haggis.objects |
Functions for manipulating the structure of objects. |
haggis.os |
Recipes for common tasks that build on the type of thing normally found in the builtin os module. |
haggis.recipes |
Useful and mostly compact shortcuts for common operations. |
haggis.string_util |
Utilities for creating, chopping, concatenating and otherwise processing strings. |
haggis.structures |
Pure-python implementation of some useful data structures. |
haggis.threads |
Tools to help with threading. |
haggis.time |
Timing, timer, time and suchlike tools. |
haggis root package¶
haggis is the root package of the haggis library.
The root package contains the __version__, a
Sentinel singleton and its associated type.
The sub-packages and sub-modules in this library are arranged mostly by category. Some of the dependencies to the various types of utilities are optional, and the corresponding modules will only work fully if the dependencies are present. See the Extras section in the Installation Guide.
args module¶
Utilities for processing command line arguments.
This module works in conjunction with Python’s standard library
argparse module.
-
class
haggis.args.SmartHelpFormatter(*args, keep_newlines=None, keep_leading=None, tabwidth=None, **kwargs)¶ A help formatter class that can keep newlines. Currently, the
argparsefunctionality can only use the default arguments. To change the defaults, extend this class with different values of the class attributes.Note: This class extends some private functionality in the API. There is no guarantee that it will work in newer versions of python. Please submit an issue if you experience any problems.
-
KEEP_NEWLINES¶ If True, manually inserted newlines will be preserved along with standard line-wrapping behavior.
-
KEEP_LEADING¶ If True, manually inserted leading spaces will be preserved while performing standard line-wrapping behavior and indentation.
-
TABWIDTH¶ If
KEEP_LEADINGis True, this attribute determines the number of spaces by which a\tcharacter is replaced by, while preserving indentation.
-
configuration module¶
Recipes for handling different types of configuration files.
-
class
haggis.configuration.JSONConfiguration(source)¶ Class for managing loading and updating JSON configurations.
The file into its just loaded into the namespace __dict__. The metadata attributes are stored in __slots__, so do not interfere with the configuration keys. In particular, the following metadata key is supported:
-
_source¶ The source file or mapping for the configuration.
Child classes should extend
_reloadto parse the necessary keys directly in their own namespace, and to do any error checking on the loaded data. Conversely, children should extend_updateto perform any additional steps necessary to serialize back into a file.Methods and attibutes are not private: the single underscores are intended to reduce the probablility of shadowing a configuration key.
-
_check_path(*keys)¶ Ensure that a given sequence of nested namespaces exists in this namespace.
All keys in the sequence besides the last one must contain a mutable
__dict__. If the last item in the sequence does not exist, it will be created as aNamespace.Parameters: *keys – Sequence of keys to verify. Any missing keys will be created as empty namespaces. An error will be raised if an intermediate object exists without a mutable __dict__. Returns: - The object at the end of the chain. If keys is empty, returns
- the current object.
-
_pprint(filename=None, *, indent=4, root_indent=False, linewidth=120, float_format='', int_format='', bool_format=True, bytes_format='utf-8', exclude=())¶ Pretty print the configuration into a file.
All arguments besides the file name are keyword-only. Output formats for additional datatypes besides the normal JSON types are supported by registering
JSONObjectdescriptors usingjson_registry.register.Parameters: - filename (str or Path or file-like) – The file to write to. If an open file, must have write
permissions. If a string or path, will be truncated or
created (using
'w'mode). - indent (int) – The number of spaces to indent nested objects by. Default 4.
- root_indent (bool) – Whether or not to indent the root namespace. Default is not to.
- linewidth (int) – The number of characters to attempt to wrap arrays at. Default is 120.
- bytes_format (str) – Name of the encoding to use to convert byte arrays to string. If None, record byte arrays as arrays of hexadecimal integers.
- exclude (iterable) – An iterable of items to exclude from the printout. Hashable elements are interpreted as top-level keys. Nested elements must be specified as a list of keys.
- filename (str or Path or file-like) – The file to write to. If an open file, must have write
permissions. If a string or path, will be truncated or
created (using
-
_reload(source=None)¶ Load the specified file (or the default
_filename).Any nested mapping objects are replaced with
Namespace.Override this method to implement additional conversion or error checking functionality.
Parameters: source (str or Path or Mapping, optional) – If supplied, replace the default source for this configuration.
-
_update(source=None, *exclude)¶ Write the dictionary back to the file or original mapping.
If writing to a mapping, convert nested
Namespaces todict.Override this method to implement additional conversion or error checking functionality.
Parameters: - source (str or Path or Mapping, optional) – If provided, supplies a non-default destination for the
namespace, but does not permanently replace
_source. The default is None. - *exclude – sequence of keys to exclude. Hashable types are keys in the
current dictionary. Lists indicate multi-level keys. For
example, to avoid printing
self.a.b, add an exclude['a', 'b'].
- source (str or Path or Mapping, optional) – If provided, supplies a non-default destination for the
namespace, but does not permanently replace
-
-
class
haggis.configuration.JSONObject(type)¶ Base class of additional output formatting types.
To register a new formatter use the module-level
json_registry.registerfunction.-
type¶ The type or types supported by this formatter. Any object that is a valid second argument to
isinstanceis accepted.
-
format(file, obj, prefix, indent)¶ Format an object for output to a file.
The base class method is a no-op and should be overriden by subclasses.
Parameters:
-
-
class
haggis.configuration.NumpyObject(printopts=None, type=<class 'numpy.ndarray'>)¶ Type of
JSONObjectspeficic to numpy arrays.An instance of this class is registered automatically.
-
_PRINTOPTS= {'floatmode': 'fixed', 'formatter': {'bool': <function NumpyObject.<lambda>>}, 'max_line_width': 120, 'precision': 18, 'separator': ', ', 'sign': ' ', 'suppress_small': False, 'threshold': 9223372036854775807}¶ Format spec to use for numpy arrays.
Must not contain a
'prefix'key, which will be silently purged if present.
-
format(file, obj, prefix, indent)¶ Pretty-print a numpy array with the specifed indentation.
-
-
haggis.configuration.json_registry= [<haggis.configuration.NumpyObject object>]¶ A list-like object with an additional
registermethod.-
json_registry.register(formatter: JSONObject)¶ Call this function to add output types to be used with
JSONConfiguration._pprint.
-
json_registry.clear()¶ Call this function to clear the registry.
An instance of
NumpyObjectwith default parameters is registered automatically.-
ctypes_util module¶
Utilities and recipes for extending ctypes functionality.
-
haggis.ctypes_util.c_bool_p¶ alias of
haggis.ctypes_util.LP_c_bool
-
haggis.ctypes_util.c_byte_p¶ alias of
haggis.ctypes_util.LP_c_byte
-
haggis.ctypes_util.c_double_p¶ alias of
haggis.ctypes_util.LP_c_double
-
haggis.ctypes_util.c_float_p¶ alias of
haggis.ctypes_util.LP_c_float
-
haggis.ctypes_util.c_int_p¶ alias of
haggis.ctypes_util.LP_c_int
-
haggis.ctypes_util.c_int8_p¶ alias of
haggis.ctypes_util.LP_c_byte
-
haggis.ctypes_util.c_int16_p¶ alias of
haggis.ctypes_util.LP_c_short
-
haggis.ctypes_util.c_int32_p¶ alias of
haggis.ctypes_util.LP_c_int
-
haggis.ctypes_util.c_int64_p¶ alias of
haggis.ctypes_util.LP_c_long
-
haggis.ctypes_util.c_long_p¶ alias of
haggis.ctypes_util.LP_c_long
-
haggis.ctypes_util.c_longdouble_p¶ alias of
haggis.ctypes_util.LP_c_longdouble
-
haggis.ctypes_util.c_longlong_p¶ alias of
haggis.ctypes_util.LP_c_long
-
haggis.ctypes_util.c_short_p¶ alias of
haggis.ctypes_util.LP_c_short
-
haggis.ctypes_util.c_size_t_p¶ alias of
haggis.ctypes_util.LP_c_ulong
-
haggis.ctypes_util.c_ssize_t_p¶ alias of
haggis.ctypes_util.LP_c_long
-
haggis.ctypes_util.c_ubyte_p¶ alias of
haggis.ctypes_util.LP_c_ubyte
-
haggis.ctypes_util.c_uint_p¶ alias of
haggis.ctypes_util.LP_c_uint
-
haggis.ctypes_util.c_uint8_p¶ alias of
haggis.ctypes_util.LP_c_ubyte
-
haggis.ctypes_util.c_uint16_p¶ alias of
haggis.ctypes_util.LP_c_ushort
-
haggis.ctypes_util.c_uint32_p¶ alias of
haggis.ctypes_util.LP_c_uint
-
haggis.ctypes_util.c_uint64_p¶ alias of
haggis.ctypes_util.LP_c_ulong
-
haggis.ctypes_util.c_ulong_p¶ alias of
haggis.ctypes_util.LP_c_ulong
-
haggis.ctypes_util.c_ulonglong_p¶ alias of
haggis.ctypes_util.LP_c_ulong
-
haggis.ctypes_util.c_ushort_p¶ alias of
haggis.ctypes_util.LP_c_ushort
-
haggis.ctypes_util.check_zero(fail_msg, error=<class 'ValueError'>, name_prefix=True)¶ Generate an error checker for the specified message and error type.
The resulting function can be set as the
errcheckof actypesfunction. It will raise an error on truthy return values and pass through zeros.Parameters: - fail_msg (str) – Messages may be new-style interpolation strings that index the
function arguments and include the names
__func__and__value__as a keywords. - error (type) – The type of error to raise if the result is truthy.
- name_prefix (str or bool) – If name_prefix is a string, it gets prepended to the message
directly. If any other truthy value,
'{__func__}: 'gets prefixed instead. Falsy values don’t modify the message at all. String prefixes can contain interpolations themselves.
Returns: A function named check_zero that accepts arguments named
value,func, andargumentsand raises an error ifvalueis truthy.Return type: callable
- fail_msg (str) – Messages may be new-style interpolation strings that index the
function arguments and include the names
-
haggis.ctypes_util.check_nonzero(fail_msg, error=<class 'ValueError'>, name_prefix=True)¶ Generate an error checker for the specified message and error type.
The resulting function can be set as the
errcheckof actypesfunction. It will raise an error on falsy return values and pass through the return value otherwise.Parameters: - fail_msg (str) – Messages may be new-style interpolation strings that index the function arguments and include the name __func__ as a keyword.
- error (type) – The type of error to raise if the result is falsy.
- name_prefix (str or bool) – If name_prefix is a string, it gets prepended to the message
directly. If any other truthy value,
'{__func__}: 'gets prefixed instead. Falsy values don’t modify the message at all. String prefixes can contain interpolations themselves.
Returns: A function named check_nonzero that accepts arguments named
value,func, andargumentsand raises an error ifvalueis falsy.Return type: callable
-
haggis.ctypes_util.decode_c_char_p(encoding='utf-8', null_error=False)¶ Generate an error checker that decodes strings with a custom encoding.
The resulting function can be set as the
errcheckof actypesfunction. It decodes the bytes of a char * to a python string.Checkers returned by this function are cached, for efficiency when using multiple times on the same encoding.
Parameters: Returns: A function named decode_as_ followed by the target encoding that accepts arguments named
value,func, andargumentsand decodesvalueusing the specified encoding.Return type: callable
-
haggis.ctypes_util.make_enum(enum_type)¶ Generate an error checker that converts to the specified enum.
The resulting function can be set as the
errcheckof actypesfunction. It converts the return value into a Python enum.Checkers returned by this function are cached, for efficiency when using multiple times on the same enum_type.
Parameters: enum_type (callable) – Normally, this is a subclass of IntEnum, which converts a C return value into the appropriate type. However, this may be any arbirary callable, as long as it has a__name__attribute.Returns: A function named make_ followed by the __name__of enum_type that accepts arguments namedvalue,func, andargumentsand convertsvalueto the target type.Return type: callable
-
haggis.ctypes_util.to_c_char_p(s, encoding='utf-8')¶ Convert a string into a NUL-terminated
bytes.Parameters: Returns: The encoded string, terminated by
b'\'.Return type:
-
class
haggis.ctypes_util.CDLLWrapper(name, *folders, prefix='', index=None)¶ Wrapper for full-path DLLs to make them closeable and manage dependencies.
This class is mostly useful for Windows, since it manages dependency folders. The only purpose it serves on UNIX-like systems is to close the library handle.
-
close()¶ Close this library, if it is open.
If not open, this is a no-op.
Any cached function objects are deleted, and the underlying binary is closed.
On Windows, the dependency folders are unloaded after closing the DLL itself.
-
open()¶ (Re)open this library, if it is closed.
If already open, this is a no-op.
On Windows, the dependency folders are added prior to opening the DLL itself.
-
exceptions module¶
Utilities for implementing, raising and handling exceptions.
-
class
haggis.exceptions.ErrorTransform(in_type, out_type, message, *args, **kwargs)¶ A context manager that translates any exceptions into a different type with a predefined message. The constructor arguments are assigned to class attributes directly.
-
in_type¶ The exceptions to look for, in any format accepted by an
exceptclause: a single type or a tuple of types.
-
out_type¶ The type to reraise as.
-
message¶ A format string containing the message of the rethrown error. The string is expected to conform to the Format Specification Mini-Language.
-
args¶ Additional positional arguments to pass to
message.format.
-
kwargs¶ Additional keyword arguments to pass to message.format. There three dynamic keywords are always passed in:
type: The class of the trapped error.str: The result ofstr(exc)on the trapped error.repr: The result ofrepr(exc)on the trapped error.
These three names must not appear as keys in kwargs.
-
classmethod
KeyError(out_type, name='dictionary')¶ Create an instance of this class suitable for handling occurrences of
KeyErrorcaused by, e.g. dictionary access via__getitem__.in_typeis implicitlyKeyErrorand name is the name of the dictionary where the error occurred.
-
files package¶
Routines for dealing with file types.
The module names in this package generally correspond to the informal name of the file type they deal with, or to the extension.
-
haggis.files.ensure_extension(name, ext, partial_policy=None, partial_limit=None)¶ Verify that the name ends with the required extension, and update it if not.
name is assumed to be a string. ext is the desired suffix, usually beginning with
'.'. If name aleady ends with ext, return it as-is. If not, the extension will either be appended or completed depending on partial_policy and partial_limit. The first character of ext is treated as the separator character. It must appear in name for any of the completions to work.Recognized values for partial_policy are as follows (case insensitive):
None,'none',''- No partial extensions are recognized. If
name='a.xls'andext='.xlsx', the result is'a.xls.xlsx'. Similarly, for'b.jpg','.jpeg', the result is'b.jpg.jpeg'. 'append','+'- Existing extension can be extended by at most
partial_limit characters to acheive the target. If
name='a.xls'andext='.xlsx', the result is'a.xlsx'. However, for'b.jpg','.jpeg', the result is'b.jpg.jpeg'. 'insert','^'- Existing extension can have up to partial_limit characters
inserted anywhere to achieve the target. If
name='a.xls'andext='.xlsx', the result is'a.xlsx'. Similarly, for'b.jpg','.jpeg', the result isb.jpeg. 'strip','-'- The existing extension may be loner than the desired one, so
up to partial_limit characters may be stripped off the end
to match the target. If
name='a.xlsx'andext='.xls', the result is'a.xls'. However, for'b.jpeg','.jpg', the result is'b.jpeg.jpg'. 'remove','x'- The existing extension may be longer than the desired one,
so removing up to partial_limit characters anywhere in the
name is allowed. If
name='b.jpeg'andext='.jpg', the result is'b.jpg'. However, forname='b.jpg'andext='.jpeg', the result is'b.jpg.jpeg'. 'replace','r'- Replace any existing extension with the provided one.
'create','c'- Create the extension only if one does not already exist.
partial_limit determines the maximum number of characters that can be modified to achieve the target. If
Noneor a number greater than the length of ext mean “any number”. If zero, the result is the same as for partial_policy=’none’ regardless of the actual value of partial_policy, unless partial_policy is'replace', which completely ignores the limit.
-
haggis.files.insert_suffix(filename, suffix, n=0, allow_duplicate=False)¶ Insert a suffix into the file name before the extension.
Append the suffix if there is no extension. By default, if the suffix is already present, it is not duplicated.
Parameters: - filename (str or Path) – The name to modify.
- suffix (str) – The suffix to insert.
- n (int, optional) – The extension after which to insert the suffix. Indexing
similar to list indexing, with
n=0referring to the base name andn=-1the last extension. In"a.b.c.d",".d"is atn=3orn=-1,"a"is atn=0orn=-4. The default is to prepend to the base name:n=0. - allow_duplicate (bool) – If
True, no check will be made to see if the suffix is already present. IfFalse(the default), the suffix will only be inserted if not already present.
Returns: inserted – The modified name.
Return type:
-
haggis.files.open_file(file, *args, **kwargs)¶ Return an open file-like object for the input.
If the input is already a file-like object (not a string, path, or file descriptor), a proxy for it is returned. The original object remains unmodified. The proxy can be used in a context manager, but it will not close the file when exiting.
Strings, paths and file descriptors are opened using the additional arguments provided. They return a true file object that will close itself when used as a context manager.
Returns: file – A file-like opened from the file input. Return type: file-like
-
haggis.files.split_extension(filename, max=None)¶ Upgraded version of
os.path.splitextthat splits apart all the available extensions.Parameters: Returns: parts – A list containing the base name and up to max extensions. Any unsplit extensions will still be attached to the base name.
Return type:
-
class
haggis.files.PreOpenedFile(file)¶ A proxy class for file objects that does not open or close the file when
__enter__,__exit__andcloseare invoked.This version of the usual context manager is useful when processing opened files along with strings.
Note that this is not a general-purpose proxy that can be used for most objects because it does not define any special methods besides
__repr__,__enter__,__exit__,__iter__andcloseas class attributes.-
__enter__(*args, **kwargs)¶ Return this proxy object.
-
__exit__(*args, **kwargs)¶ Do nothing.
-
__iter__(*args, **kwargs)¶ Return an iterator over the underlying file.
-
__repr__()¶ Return a string representation of the underlying file.
-
close()¶ Do nothing.
-
files.csv module¶
Utilities for processing CSV files.
Among other things, this module registers a ‘text’ dialect with the
built-in csv module, suitable for ingesting plain text
arranged in space-separated colmns.
-
haggis.files.csv.load_as_numbers(file, header_lines=0, dialect='text', format='normal', empty=nan, **kwargs)¶ Load a CSV file as a numbers.
Parameters: - file (str or file-like) – Strings are assumed to be file names and opened. Other file-like objects are not closed when this function returns.
- header_lines (int) – The number of lines to skip from the beginning of the file.
- dialect (str or csv.Dialect) – The dialect to use. String options can be obtained from
csv.list_dialects. - format (str) –
One of the following data formats to use for the return value:
'normal': Return as a list of rows.'transpose': Return a list of columns.'numpy': Return a numpy array.
- empty (number) – The value to use for empty strings.
- kwargs (dict) – Any additional parameters to pass to
csv.reader.
Raises: ValueError– If any of the elements of the file can not be converted to afloatorint.
-
haggis.files.csv.load_as_columns(file, header_lines=0, empty=nan, dialect='text', **kwargs)¶ Load a CSV file as sequence of columns rather than rows.
Parameters: - file (str or file-like) – Strings are assumed to be file names and opened. Other file-like objects are not closed when this function returns.
- header_lines (int) – The number of lines to skip from the beginning of the file.
- dialect (str or csv.Dialect) – The dialect to use. String options can be obtained from
csv.list_dialects. - empty (number) – The value to use for missing elements. If
None, the data may not be ragged: each line must contain the same number of fields as the first. - kwargs (dict) – Any additional parameters to pass to
csv.reader.
Raises: ValueError– If the file contains a ragged array and empty is set toNone.
-
haggis.files.csv.reformat(data, format='normal')¶ Convert a normal CSV dataset stored by rows into a different format.
Valid formats are
'normal': Return as a list of rows.'transpose': Return a list of columns.'numpy': Return a numpy array.
files.docx module¶
Utilities for working with new-style MS Word documents, only available
when the [docx] extra is installed.
If python-docx is not found at import time, this module will have a
docx_enabled attribute, which will be False. If
python-docx is found, on the other hand, docx_enabled will
be True, and all the functions and attributes of the module
will be present.
Some of the methods here are workarounds for features that are missing or buggy in the original library. Often, these methods are inspired by recipes found in the corresponding bug reports and Stack Overflow posts, which are referenced as appropriate.
-
haggis.files.docx.docx_enabled¶ A boolean value indicating whether the
[docx]extra has been installed. IfFalse, the API will be severely limited.
-
haggis.files.docx.block_iterator(parent)¶ Yield each paragraph and table child within parent, in document order.
Each returned value is an instance of either
TableorParagraph. parent would most commonly be a reference to a mainDocumentobject, but also works for a_Cellobject, which itself can contain paragraphs and tables.This function is taken verbatim from python-docx Issue #40. Hopefully it will make it to python-docx soon.
-
haggis.files.docx.insert_toc(doc, min_level=1, max_level=3)¶ Insert a table of contents stub into a
Document.The TOC is a stub and needs to be updated manually when the end-user opens the generated document in a Word client.
This function is taken almost verbatim from @mustash’s comment to python-docx Issue #36. See the previous comment in the thread for more information.
-
haggis.files.docx.merge_row(table, row=0)¶ Merge a row in a
Tableinto a single cell.Operates on the first row by default.
-
haggis.files.docx.set_row_height(row, height)¶ Set the height of a
docx.table.Tablerow.Parameters: - row (docx.table._Row) – The row index.
- height (docx.shared.Length) – The height to assign.
This function will be obsolted by python-docx Pull Request #301.
-
haggis.files.docx.style_row(doc, style, *args)¶ -
haggis.files.docx.style_row(doc, style, row)
-
haggis.files.docx.style_row(doc, style, table, rowid)
Set a custom style for all the text in a row in the table.
Every paragraph of each cell in the row will be styled, so use with care.
Parameters: - doc (docx.document.Document) – The document containing the items to style. Only required when style is set by name.
- style (docx.styles.style._CharacterStyle or docx.styles.style._ParagraphStyle or str) – The name or style object representing a run- or paragraph-level style to apply.
- row (docx.table._Row) – The row object to style.
- table (docx.table.Table) – The table to style.
- rowid (int) – The index of the row to style.
-
-
haggis.files.docx.style_column(doc, style, *args)¶ -
haggis.files.docx.style_column(col, *, style)
-
haggis.files.docx.style_column(table, colid, *, style)
Set a custom style for all the text in a column in the table.
Every paragraph of each cell in the column will be styled, so use with care.
Parameters: - doc (docx.document.Document) – The document containing the items to style. Only required when style is set by name.
- style (docx.styles.style._CharacterStyle or docx.styles.style._ParagraphStyle or str) – The name or style object representing a run- or paragraph-level style to apply.
- col (docx.table._Column) – The column object to style.
- table (docx.table.Table) – The table to style.
- colid (int) – The index of the column to style.
-
-
haggis.files.docx.table_no_fill(table)¶ Set the table not to fill up the entire page width.
This should be called after the table has been filled in, or at least the number of rows and columns has been set. Adding rows and columns may cause unpredictable layout conflicts which may invalidate these settings.
This method is a result of research done on https://github.com/python-openxml/python-docx/issues/315.
-
haggis.files.docx.edit_font(doc, runs, **kwargs)¶ Adds a dynamic run-style to the document that changes the font properties of the specified runs.
The updated style is generated on the fly and inherits all properties except the ones that are modified from the current character style of the run. The style name is the original style name with the modified properties appended after a
+or-sign, in alphabetical order. If such a character style already exists in the document, it will be used instead of making a new one.The runs parameter is expected to generally come from the
runsattribute of aParagraphobject. A singleRuncan be processed as well.Parameters: - doc (docx.document.Document) – The document containing the runs to modify. This is necessary because the styles must be added to the document.
- runs (iterable[docx.text.run.Run] or docx.text.run.Run) – Either an iterable or runs or a single run. The runs will be given a new character style that inherits from the current one but contains an updated font with the requested color.
- name (str) – The name of the font.
Noneif not to be modified. Added as... + "NAME". - size (float or int) – The font size in points.
Noneif not to be modified. Added as... + SIZEpt. - color (tuple(int, int, int)) – A three-element tuple of integers that represents the RGB
components of the color to set, or None if color is not to
be modified. Other iterables are accepted, but they are
converted to tuples internally. Added as
... + rgb(R,G,B).
All remaining arguments are processed as tri-state booleans, where
Noneindicates no modification. Flags are appended as... + FLAGifTrue,... - FLAGifFalse. Supported arguments flags are:- bold
- italic
- underline
- subscript
- superscript
- all_caps
- emboss
- strike
- double_strike
- imprint
- outline
- shadow
- small_caps
-
haggis.files.docx.is_paragraph_empty(paragraph)¶ Check if a paragraph contains content.
Content includes any item besides styling information and empty runs.
-
haggis.files.docx.delete_paragraph(paragraph)¶ Remove a paragraph from an enclosing document.
This may or may not work properly if the paragraph contains non-trivial content, like pictures.
Inspiration is from @scanny’s comment regarging python-docx Issue #33.
-
haggis.files.docx.list_number(doc, par, prev=None, level=None, num=True)¶ Make a paragraph into a list item with a specific level and optional restart.
An attempt will be made to retreive an abstract numbering style that corresponds to the style of the paragraph. If that is not possible, the default numbering or bullet style will be used based on the num parameter.
Parameters: - doc (Document) – The document to add the list into.
- par (Paragraph) – The paragraph to turn into a list item.
- prev (Paragraph or None) – The previous paragraph in the list. If specified, the numbering and styles will be taken as a continuation of this paragraph. If omitted, a new numbering scheme will be started.
- level (int or None) – The level of the paragraph within the outline. If prev is set, defaults to the same level as in prev. Otherwise, defaults to zero.
- num (bool) – If prev is
Noneand the style of the paragraph does not correspond to an existing numbering style, this will determine wether or not the list will be numbered or bulleted. The result is not guaranteed, but is fairly safe for most Word templates.
Note
The code here is mainly taken from python-docx Issue #25 and Pull Request #110 In particular, see the two comments by @yurac: [1] and [2]
-
haggis.files.docx.add_section(doc, orientation=0)¶ Add a new section to doc with the specified page orientation.
This function always creates a new section with page break style WD_SECTION_START.NEW_PAGE, even if the previous section has the same orientation. The width and height of the new section will be swapped if necessary so that the width is greater in landscape mode and the height is greater in portrait mode.
orientation may be one of the WD_ORIENTATION enums, or the strings {
'portrait','landscape'} (case insensitive).Returns the newly created section.
This function is a workaround for python-docx bug #214. The same workaround is also described in http://stackoverflow.com/q/31893557/2988730.
-
haggis.files.docx.insert_math_ml(par, math_ml)¶ Convert a MathML equation to an Open MathML format suitable for MS documents, and insert it into the specified paragraph.
The MathML is converted to Open MathML format using an internal stylesheet and inserted into the end of the paragraph.
Parameters: Notes
If the MML to OMML stylesheet can not be located for any reason, this function will raise a
NotImplementedError. The error will indicate the expected location of the file.This function and its setup are based on the discussion of issue #320 on the python-docx GitHub page. The file MML2OMML.XSL was provided by user @peepall as part of the discussion.
-
haggis.files.docx.str2length(string, default_units='"')¶ Convert a string with a floating point number and associated units into a
docx.shared.Length.The number and the units may be separated by optional whitespace. If the units are missing entirely, default_units will be used instead. default_units may be a
docx.shared.Lengthsubclass, or a string naming the units. The default default isdocx.shared.Inches.Unit names are case insensitive. They may be written out fully or abbreviated, plural or singular.
files.fits module¶
Utilities for working with FITS files, only available when the
[scio] extra is installed.
If astropy is not found at import time, this module will have a
fits_enabled attribute, which will be False. If
astropy is found, on the other hand, fits_enabled will
be True, and all the dependent functions and attributes of the
module will be present.
-
haggis.files.fits.fits_enabled¶ A boolean value indicating whether the
[scio]extra has been installed. IfFalse, the API will be severely limited.
-
class
haggis.files.fits.TempFITS(array, filename=None, *, open_file=True, delete_on_close=True, **kwargs)¶ A context manager for storing the contents of a numpy array to a temporary FITS file.
If created successfuly, the file is deleted when the context manager exits.
-
filename¶ The name of the temporary file, either passed in directly, or generated during initialization.
-
delete_on_close¶ Indicates whether or not the underlying file will be deleted when the context manager exits. Default is
True.
-
open_file¶ Whether or not the context manager should return a file object opened for reading along with the filename when it enters. The default is to return only the filename.
-
file¶ The file handle opened by when the context manager enters, if
open_fileisTrue. At all other times, this attribute isNone.
Todo
Most of TempFITS can be factored out into a much more general base class.
-
files.pdf module¶
Conversion utilities for PDF files to other formats.
This module relies on the [pdf] extra,
which implies external programs. As such, this module may be quite
OS-sensitive. Specifically, it requires the programs pdftoppm
and ImageMagick’s convert.
A small import-guarded block is provided to demo
pdf_to_image.
-
haggis.files.pdf.pdftoppm_exe= 'pdftoppm'¶ The name of the pdftoppm executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.files.pdf.convert_exe= 'convert'¶ The name of the ImageMagick convert executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.files.pdf.pdf_to_image(input_path, output_path, format=None)¶ Convert a PDF document into an image file.
This function uses the
subprocessmodule to operate. It requires the presence of the pdftoppm program as well as convert from ImageMagick.input_path may be a string path or a file-like object.
output_path may be a string, a file-like object or
None. IfNone, anio.BytesIOobject is returned containing the image. format defaults to'png'if not set explicitly in this case.Return the name of the output file, or an in-memory file-like object (
io.BytesIO) if output_path isNone.The idea for behind this conversion mechanism comes from http://stackoverflow.com/a/2002436/2988730. The implementation details are described in http://stackoverflow.com/a/4846923/2988730.
files.ps module¶
Conversion utilities for PostScript (PS, EPS) files to other formats.
PS and EPS files are very useful formats for creating printable figures with matplotlib. They support a number of features that are difficult to achieve with other backends/formats, such as colored TeX strings.
This module relies on the [ps] extra,
which implies external programs. As such, this module may be quite
OS-sensitive. Specifically, it requires the main GhostScript (GS)
program, gs.
A small import-guarded block is provided to demo ps_to_image.
-
haggis.files.ps.gs_exe= 'gs'¶ The name of the gs executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.files.ps.ps_to_image(input_file, output_file, format='pngalpha', dpi=None)¶ Convert a PS or EPS document into an image file.
EPS files are preferred inputs because they allow for proper trimming of the output image margins.
This function uses the
subprocessmodule to operate. It requires the presence of the gs program from GhostScript.input_file may be a string path or a file-like object.
output_file may be a string, a file-like object or
None. IfNone, anio.BytesIOobject containing the image is returned.format may be either the name of MatPlotLib-like presets or the name of a GhostScript output device. The following is a list of preset formats with the GS devices that they map to:
'png':pngalpha'jpg':jpeg'bmp':bmp16m'pdf':pdfwrite
Preset names do not overlap with any output device, so any value of format not matching a preset is interpreted as a device name. See the docs at http://ghostscript.com/doc/current/Devices.htm for a complete list of available output devices.
format defaults to
'pngalpha'.Returns the name of the output file, or an in-memory file-like object (
io.BytesIO) if output_file isNone.
files.ui module¶
Utilities for interacting with the file system with an optional graphical user interface.
The GUI package is chosen based on a list of supported selections, defaulting to tkinter. Currently, only PyQt and tkinter are supported.
-
haggis.files.ui.get_existing_file(filename=None, title='Open', filters=None, sel=0)¶ Return the name of an existing file.
The file can be opened for reading unless permissions intervene.
Parameters: - filename (str, optional) – The initial file name to check. If the name exists and is a file, a GUI will not be displayed. If it is a directory, it will be used as the starting point in the GUI. The default is None.
- title (str or None) – An optional title for the dialog that will be displayed if filename does not exist.
- filters (sequence[str or tuple] or None) – A sequence or mapping of filename filters. Sequences must
consist of two-tuples with a filter name and a list of
extensions. Mappings contain a list of extensions as values. If
None, no filtering will be done in the dialog. Filter extensions
may contain a leading
'*.', but are not required to contain either character. - sel (str or int) – An optional key into filters, ignored if filters is None.
Returns: filename – The name of an existing file, or None if the user changes their mind.
Return type:
files.xlsx module¶
Utilities for working with new-style MS Excel documents, only available
when the [xlsx] extra is installed.
If openpyxl is not found at import time, this module will have a
xlsx_enabled attribute, which will be False. If
openpyxl is found, on the other hand, xlsx_enabled will
be True, and all the dependent functions and attributes of the
module will be present.
-
haggis.files.xlsx.xlsx_enabled¶ A boolean value indicating whether the
[xlsx]extra has been installed. IfFalse, the API will be severely limited.
-
haggis.files.xlsx.EXTENSION= '.xlsx'¶ The extension that will be appended to output file names by
ensure_extension.
-
haggis.files.xlsx.ensure_extension(output)¶ Verify that the output object is a valid file name, and return a fixed version if not.
If output is a
strand does not end with'.xlsx', fix it. If it ends with'.xls', append'x', otherwise append'.xlsx'. All other types are assumed to be proper file-like objects that are passed through.
-
haggis.files.xlsx.apply_border(ws, start_row, end_row, start_column, end_column, *, merge=False, **kwargs)¶ Apply a border around the specified range of cells as if it was a single object.
The border may be specified in a number of ways through keyword arguments.
If the argument border is specified, there may not be any other kwargs. If border is a
openpyxl.styles.borders.Side, apply it on all sides. If it is aopenpyxl.styles.borders.Border, apply the attributes of the border to the sides they correspond to around the whole edge.The other option is to specify kwargs as some subset of {top, left, bottom, right}. Each argument can be a
openpyxl.styles.borders.Sideor anopenpyxl.styles.borders.Border. Only the part of the border corresponding to the side of the object it goes on will be used. For example, only thetopattribute of a border specified for top will be used. The other attributes will be ignored. The borders corresponding to missing orNonearguments will not be changed in this case.This function is based heavily on the recipe described in
http://openpyxl.readthedocs.io/en/stable/styles.html#styling-merged-cells.
-
haggis.files.xlsx.copy_range(ws_in, row_in=None, column_in=None, width=None, height=None, ws_out=None, row_out=None, column_out=None, delete_empty=True)¶ Copy a range of cells from one worksheet to another.
All arguments besides ws_in are technically optional, with some restrictions. This allows shortcuts for copying blocks between or even within worksheets.
Warning
At this time, copying into the same worksheet may yield incorrect results if the source and destination overlap.
Parameters: - ws_in (openpyxl.worksheet.worksheet.Worksheet) – The source worksheet with the data.
- row_in (int or None) – The row of the upper-left hand corner in the source. If
None, single-column mode will be used. In this case, width may not be specified and efectively becomes1. - column_in (int or None) – The column of the upper-left hand corner of the source. If
None, single-row mode will be used. In this case,heightmay not be specified and efectively becomes1. - width (int or None) – The width (number of columns) of the range. If
None, all available columns will be used. - height (int or None) – The height (number of rows) of the range. If
None, all available rows will be used. - ws_out (openpyxl.worksheet.worksheet.Worksheet) – The destination worksheet. If omitted, defaults to the source worksheet. In that case, the location being copied to must be different.
- row_out (int or None) – The row of the upper-left hand corner in the destination. If omitted, defaults to the same location as the source.
- column_out (int or None) – The column of the upper-left hand corner in the destination. If omitted, defaults to the same location as the source.
- delete_empty (bool) – Whether or not to remove destination cells that are
overwritten by missing cells in the source range. Default is
True.
Only one of row_in and column_in may be
None. All indices are one-based to conform to openpyxl notation.Returns: n – The number of non-empty source cells copied. This will be zero if the destination is the same as the source. Return type: int
files.xml module¶
Utilities for extending and configuring the Python XML framework.
-
class
haggis.files.xml.SAXBase¶ An empty SAX parser with some convenience functionality built in.
This class provides a reference to the locator. All of the actual SAX callback methods are currently no-ops.
-
locate(message, *args, short=False)¶ Convert a message and argument-list to a message with location information, and extends the argument list appropriately.
Return a tuple containing two elements: the message and the argument list as a single tuple that can be expanded into the argument of any of the logging methods.
The full version of the location string (default) includes the file name, the line number and the column. The short version only inculdes the line number and column.
-
-
class
haggis.files.xml.SAXLoggable¶ A type of
SAXBasethat provides logging in addition to location methods.-
log(level, msg, *args, **kwargs)¶ Append location information to a log message.
This method allows an additional keyword argument short that determines whether or not the full file name will be present in the location. short is
Trueby default, meaning that only the line and column number are reported.
-
files.zip module¶
Utilities for working with zip archives.
-
haggis.files.zip.filter(zipname, *filenames, filter=None)¶ -
haggis.files.zip.filter(zipname, *filenames, filter=None)
-
haggis.files.zip.filter(zipname, filterDict)
Modify the contents of a file or files in the specified zip archive.
A filter value of
Noneremoves the selected files.There are two calling conventions for this function. In the first case, it accepts a sequence of file names or
zipfile.ZipInfoobjects. filter is a function that accepts a byte string with the decompressed file contents and returns the filtered string to replace the contents with. The filtered string may be a true string or bytes.In the second case, filter is not provided separately, but rather as the values in a mapping. The keys are the file names to filter. This version is only activated when there is a single additional argument besides zipname. In this case filter is completely ignored.
File contents ares re-inserted with the same metadata as the original.
-
-
haggis.files.zip.remove(zipname, *filenames)¶ Remove the specified file from the named zip archive.
Elements of filenames may be strings or
zipfile.ZipInfoobjects. In the latter case, only thefilenameattribute is used to identify matches. The other metadata is ignored.Raise a warning for any file names that are not found. Actual removal is done by recreating the archive minus the filtered elements in a temporary file, then overwriting the original with it.
latex_util module¶
Utilities for processing bits of latex using matplotlib for rendering.
The matplotlib setup routines are based on http://stackoverflow.com/a/38008501/2988730.
This module relies on the [plot] and [latex]
extras. The render_latex function
does not rely on [plot]. All the other functions work with
matplotlib. See haggis.mpl_util.plot_enabled.
-
haggis.latex_util.add_use_package(package_name)¶ Add a single package via
\usepackage{package_name}to the list of matplotlib’s LaTeX imports.Imports can be added to
text.latex.preambleorpgf.preambleRC keys, depending on the current backend. Packages are also automatically added to the preamble of non-MPL rendered LaTeX.
-
haggis.latex_util.render_latex(formula, file=None, format='png', *, fontsize=12, dpi=None, transparent=False, bgcolor='white', fgcolor='black')¶ Render a simple LaTeX formula into an image using external programs.
If file is
None(the default), return aBytesIOobject containing the rendered image in PNG format. The stream is rewound, so can be read immediately. Otherwise, output to the specified file (which may be a file name string or any file-like object).The sequence of system commands run by this function is based largely on text2im (http://www.nought.de/tex2im.php).
-
haggis.latex_util.package_list= ['amsmath', 'color', 'dashrule']¶ The list of packages loaded into the LaTeX preamble when this module is imported. This list gets updated with every call to
add_use_package. This allowssetup_mplto work correcly even when backends are changed under the[plot]extra.
-
haggis.latex_util.latex_exe= 'latex'¶ The name of the latex executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.latex_util.dvips_exe= 'dvips'¶ The name of the dvips executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.latex_util.convert_exe= 'convert'¶ The name of the ImageMagick convert executable. Either a full path, or a program that the shell can find on the
PATHis necessary.
-
haggis.latex_util.setup_mpl()¶ Sets up the packages that should be used by matplotlib’s LaTeX processor.
In addition to ensuring that some basic packages are imported in the preamble, this method enables latex usage in matplotlib text elements such as titles and axis labels.
This method must be called manually by any package wishing to use
render_latex_mplwith full capabilities. It should be used when the backend is changed to and from'pgf'as well.
-
haggis.latex_util.render_latex_mpl(formula, file=None, fontsize=12, **kwargs)¶ Render a simple LaTeX formula into an image using matplotlib figures.
If file is
None(the default), returns aBytesIOobject containing the rendered image in the specified format. The stream is rewound, so can be read immediately. Otherwise outputs to the specified file (which may be a file name string or any file-like object).All arguments besides file and fontsize are passed through to
matplotlib.figure.Figure.savefig.This method is based on the following Stack Overflow answer: http://stackoverflow.com/a/31371907/2988730
-
haggis.latex_util.pgf_tex_system= 'pdftex'¶ The name of the LaTeX PGF system, obtained from:
latex -v
load module¶
Custom module loading functionality for Python code, wrapped around
portions of importlib.
-
haggis.load.load_object(name)¶ Imports a single object by its qualified name.
name is expected to have the form
pkg.module.object, with all elements separated by dots. The last element is the name of the module-level attribute to load. The path is expected to be accessible from the normal Python path.
-
haggis.load.load_module(module, name=None, sys_module=False, injection_var=None, injection=None)¶ Load a module from a text file containing Python code.
Parameters: - module (str or pathlib.Path) – The path of the file to load.
- name (str or None) – The name under which the module is imported (its __name__
attribute). If not supplied, or a falsy value, the name is
computed from the file name, minus the extension. Setting this
parameter to
'__main__'will trigger import guards. - sys_module (bool) – If truthy, add the module to
sys.modulesunder the correct name. Set this to True if importing files that contain relative imports. The default is False. - injection – Any object that the user wishes to inject into the loading process. The object is visible to the code of the module under the name given by injection_var.
- injection_var (str or None) – The name of an attribute to inject into the loading process. The injection object is bound to this name the in the module namespace. The value of injection is never inspected. It is injected or omitted based solely on the contents of this parameter. A falsy value (the default) skips injection.
-
haggis.load.module_as_dict(module, name=None, *, injection=None, injection_var=None, recurse_injection=True, include_var='__include_files__', skip_dunder=True, skip_modules=True, skip_classes=False, skip_functions=False)¶ Load Python module code as a dictionary.
This function is intended to support the loading of configuration files that use valid Python code into a dictionary. The loaded module will not be inserted into
sys.modules.Basic filtering of the loaded namespace is supported: dunder attributes and imported modules are omitted from the final result by default. This behavior can be altered with the skip_dunder and skip_modules parameters, respectively.
A reference can be injected into the loaded module before its code is run (i.e., making it available to the module code) using the injection and injection_var parameters. injection is the data itself. It is never inspected or modified in any way. injection_var names the module attribute that injection will be bound to. If the module defines a variable with the same name as injection_var, the injected reference will have no effect.
If a loaded module contains an attribute named by the include_var parameter, it must be a sequence of paths or strings. All names in the sequence will be loaded recursively into the same dictionary as well. Includes will be loaded and parsed with the same parameters as the root file (except for name and possibly injection_var), in breadth-first order. Successive levels do not override values set by the root module that this function is called with. In the model for which this function was developed, configuration files can reference and override default static configurations provided externally through include files.
Parameters: - module (str or pathlib.Path) – The path of the module to load.
- name (str or None) – The name under which the module is imported (its __name__
attribute). If not supplied, or a falsy value, the name is
computed from the file name, minus the extension. Setting this
parameter to
'__main__'will trigger import guards. - injection – Any object that the user wishes to inject into the loading process. The object is visible to the code of the module under the name given by injection_var.
- injection_var (str or None) – The name of an attribute to inject into the loading process. The injection object is bound to this name the in the module namespace. The value of injection is never inspected. It is injected or omitted based solely on the contents of this parameter. A falsy value (the default) skips injection.
- recurse_injection (bool) – Whether or not to provide injection to recursively loaded modules (based on include_var). If recursion is enabled (the default), the same variable name is reused.
- include_var (str or None) – The name of the attribute to look into to find additional
include files. Defaults to
'__include_files__'. If Falsy, do not recurse. - skip_dunders (bool) – Whether or not to skip attributes starting with a double
underscore (
__) when converting to a dictionary. Defaults toTrue. - skip_modules (bool) – Whether or not to skip module objects that are found in the
loaded namespace when converting to a dictionary. Defaults to
True. - skip_classes (bool) – Whether or not to skip class objects that are found in the
loaded namespace when converting to a dictionary. Defaults to
False. - skip_functions (bool) – Whether or not to skip function objects that are found in the
loaded namespace when converting to a dictionary. Defaults to
False.
logs module¶
Utilities for extending and configuring the logging framework.
This module is called logs instead of logging to avoid conflicts
with the builtin module. Since this module is a helper, it is expected
to be imported alongside the builtin module.
-
haggis.logs.KEEP= 'keep'¶ When adding a new logging level, with
add_logging_level, silently keep the old level in case of conflict.
-
haggis.logs.KEEP_WARN= 'keep-warn'¶ When adding a new logging level, with
add_logging_level, keep the old level in case of conflict, and issue a warning.
-
haggis.logs.OVERWRITE= 'overwrite'¶ When adding a new logging level, with
add_logging_level, silently overwrite any existing level in case of conflict.
-
haggis.logs.OVERWRITE_WARN= 'overwrite-warn'¶ When adding a new logging level, with
add_logging_level, overwrite any existing level in case of conflict, and issue a warning.
-
haggis.logs.RAISE= 'raise'¶ When adding a new logging level, with
add_logging_level, raise an error in case of conflict.
-
haggis.logs.add_logging_level(level_name, level_num, method_name=None, if_exists='keep', *, exc_info=False, stack_info=False)¶ Comprehensively add a new logging level to the
loggingmodule and the currently configured logging class.The if_exists parameter determines the behavior if the level name is already an attribute of the
loggingmodule or if the method name is already present, unless the attributes are configured to the exact values requested. Partial registration is considered a conflict. Even a complete registration will be overwritten ifif_exists in (OVERWRITE, OVERWRITE_WARN)(without a warning of course).This function also accepts alternate default values for the keyword arguments
exc_infoandstack_infothat are optional for every logging method. Setting alternate defaults allows levels for which exceptions or stacks are always logged.Parameters: - level_name (str) – Becomes an attribute of the
loggingmodule with the valuelevel_num. - level_num (int) – The numerical value of the new level.
- method_name (str) – The name of the convenience method for both
loggingitself and the class returned bylogging.getLoggerClass(usually justlogging.Logger). Ifmethod_nameis not specified,level_name.lower()is used instead. - if_exists ({KEEP, KEEP_WARN, OVERWRITE, OVERWRITE_WARN, RAISE}) –
What to do if a level with level_name appears to already be registered in the
loggingmodule:KEEP- Silently keep the old level as-is.
KEEP_WARN- Keep the old level around and issue a warning.
OVERWRITE- Silently overwrite the old level.
OVERWRITE_WARN- Overwrite the old level and issue a warning.
RAISE- Raise an error.
The default is
KEEP_WARN. - exc_info (bool) – Default value for the
exc_infoparameter of the new method. - stack_info (bool) – Default value for the
stack_infoparameter of the new method.
Examples
>>> add_logging_level('TRACE', logging.DEBUG - 5) >>> logging.getLogger(__name__).setLevel("TRACE") >>> logging.getLogger(__name__).trace('that worked') >>> logging.trace('so did this') >>> logging.TRACE 5
>>> add_logging_level('XTRACE', 2, exc_info=True) >>> logging.getLogger(__name__).setLevel(logging.XTRACE) >>> try: >>> 1 / 0 >>> except: >>> # This line will log the exception >>> logging.getLogger(__name__).xtrace('that failed') >>> # This one will not >>> logging.xtrace('so did this', exc_info=False)
The
TRACElevel can be added usingadd_trace_level.Note
Before adding new levels, please see the cautionary note here: https://docs.python.org/3/howto/logging.html#custom-levels.
- level_name (str) – Becomes an attribute of the
-
haggis.logs.add_trace_level(if_exists='keep-warn')¶ Add a new
TRACElevel to theloggingmodule.The numerical trace level is
5lower thanDEBUG. It does not log stack or exception information by default. Atracemethod will be added to theloggingmodule, to the current defaultLoggerclass, and to theLoggerAdapterclass.
-
haggis.logs.configure_logger(log_file=None, file_level='NOTSET', log_stderr=True, stderr_level='WARNING', log_stdout=False, stdout_level='INFO', format_string=None, trace_warnings=True)¶ Set up the root logger based on the input parameters.
A
TRACElevel is added to theloggingmodule. The system-level automatic exception handler is set up to log uncaught errors. Warnings will always be captured by the logger, with optional tracebacks being logged by default.Parameters: - log_file (None or str) – If not
None, messages with level greater than or equal to file_level will go to the specified file. - file_level (str) – The name of the minimum logging level that will be written to
the file log if log_file is set. Defaults to
'NOTSET'. Case insensitive. - log_stderr (bool) – If
True, messages with level greater than or equal to stderr_level will be output to standard error. Defaults toTrue. - stderr_level (str) – The name of the minimum logging level that will be output to
standard error if log_stderr is set. Defaults to
'WARNING'. - log_stdout (bool) – If
True, messages with level greater than or equal to stdout_level will be output to standard output. Defaults toFalse. If log_stderr is set as well, only levels strictly less than stderr_level will be printed to standard output. - stdout_level (str) – The name of the minimum logging level that will be output to
standard error if log_stdout is set. Defaults to
'INFO'. - format_string (str) – The log format. A missing (
None) format_string defaults to'%(asctime)s - %(name)s - %(levelname)s - %(message)s'. - trace_warnings (bool) – Whether or not to print tracebacks for actual warnings (not log
entries with a warning level) caught by the Python global
warning logger. Defaults to
True. Customwarningmethods are hooked into the logger for"py.warnings".
- log_file (None or str) – If not
-
haggis.logs.reset_handlers(handler, level='NOTSET', format=None, logger=None, filter_type=None, filter_hook=None, remove_hook=None)¶ Remove all handlers of a given class from logger (root by default), and replaces them with handler.
If a handler that is being removed has a
closemethod, it will be called, unless remove_hook is explicitly set.If both filter_type and filter_hook are set, both conditions must be met in order for a handler to be removed.
Parameters: - handler (logging.Handler) – The new handler to place in the list.
- level (str) – The case insensitive name of the minimum logging level to
set for handler. Defaults to
'NOTSET'. This will not affect the level set for the logger. - format (None or str or logging.Formatter) – Format for the log output strings.
- logger (None or logging.Logger) – The logger to set the handler for. Defaults to the root logger. Neither child nor ancestor loggers will be affected by this operation.
- filter_type (None, bool or type) – The type of objects to remove from the current list of handlers.
If a superclass of handler, it will be used as the filter
instead of
type(handler). Any other type will raise an error. IfNone, then filtering by type will be done only if filter_hook is not set. Aboolexplicitly sets filtering bytype(handler)on and off regardless of filter_hook. - filter_hook (None or callable) – A function that accepts a
Handlerand returns abool.Trueindicates that an object should be removed from the list of handlers. - remove_hook (None or callable) – A function that accepts a
Handlerand performs some additional action such as closing it. The default behavior is to invokeclose()on all handlers that are being removed if they have that method.
-
haggis.logs.LogMaxFilter(level, inclusive=True)¶ Create a level-based filter that caps the maximum allowed log level.
Levels can be compared either exclusively or inclusively to the threshold.
Parameters: Returns: A callable filter that operates on log records.
Return type: filter
Notes
This function returns a callable rather than an object with a
filtermethod, so it is not compatible with logging before Python 3.2.
-
class
haggis.logs.MetaLoggableType(name, bases, dct)¶ A metaclass for assigning a logger with a properly named channel to classes.
The logger channel will be the fully qualified name of the class including package and module prefixes.
-
__namespace__¶ If this attribute is found in the class definition, it will be prefixed to the qualified name (with a dot).
-
logger¶ This attribute is assigned to all new classes based on the name and possibly
__namespace__.
-
mapping module¶
Recipes specifically for manipulating and emulating mappings, namespaces and the like.
Implementations based on some of the recipes provided in the Python documentation, and other sources like Stack Overflow.
-
haggis.mapping.dict_merge(parent, child, keys=None, exclude=None, key=None)¶ Filter a parent dictionary and override it with values from a child, if supplied as a mapping.
Parameters: - parent (dict) – The base mapping to get the keys from.
- child (dict, value or None) – If a mapping type, child[key] will be the main value and the
remaining keys will override the values obtained from parent.
Otherwise, child will be the main value. If
None, treated as missing entirely. - keys (iterable or None) – An iterable of the keys to extract from parent and child, if
it is a mapping. Should not contain key.
Nonemeans to use all the keys of parent. - exclude (container or None) – Keys to omit from the final result, even if they are present in keys.
- key – The name of the main value in parent, if it is not overriden by child. If child is a mapping, either it or parent must contain this key. Otherwise, the value of child is the value of the key.
Returns: - main (value (opt)) – The value of the main key, only returned if key is not
None. If child is a mapping type, either it or parent will provide the key. Otherwise, it will be child itself. - selection – The selected values of parent, possibly overriden by child if it is a mapping.
-
haggis.mapping.dict_select(dic, keys=None, exclude=None, extra='ignore')¶ Filter a dictionary so only the specified keys are present.
Parameters: - dic (dict) – The dictionarty to filter.
- keys (iterable or None) – The keys to include in the output. Another dictionary may be
used since it iterates over its keys by default.
Nonemeans to use all keys. - exclude (container or None) – The keys to exclude. Anything that supports the in operator is valid here. exclude takes precedence over keys: no keys in exclude will be present in the output, even if they are present in keys.
- extra ({'ignore', 'err', 'warn'}) –
How to handle members of dic that are neither in keys nor explicitly listed in exclude:
- ignore :
- Skip over extra keys.
- err :
- Issue an error if invalid keys are found.
- warn :
- Issue a warning if extra keys are found.
Values other than ‘ignore’ will compare sets of keys.
Returns: selection – A new dict object, even if keys is a superset of the actual keys found in dic.
Return type: Notes
The default behavior is just to make a copy of dic.
-
class
haggis.mapping.mapping_context(mapping, *args, **kwargs)¶ A context manager for temporarily modifying the keys of a mapping.
The context manager has a
deletemethod that allows values to be removed as well. The method accepts any number of attribute names to delete and returns the context manager, so it can be used in a The with statement block directly. Missing key names are ignored.All mapping values are reset to their original values when the manager exits. Nesting multiple instances of this context manager has a cumulative effect.
The context manager is reentrant: the manager can be entered and exited and modified before re-entry as many times as necessary.
Sample usage:
d = {'a': 1, 'b': 2} print(d) with mapping_context(d, b=0, c=3): print(d) with mapping_context(d, b=1).delete('a'): print(d) print(d) print(d)
Will result in:
{'a': 1, 'b': 2} {'a': 1, 'b': 0, 'c': 3} {'b': 1, 'c': 3} {'b': 0, 'c': 3, 'a': 1} {'b': 2, 'a': 1}
Instances have three documented attributes:
-
mapping¶ The
dict-like object that this context manager applies to. The entire interface to the mapping is through thegetfuncandsetfuncmethods, so that a context manager for non-mapping types can be simulated by subclassing.
-
updates¶ A mapping of the added keys to their prior values. This mapping is unordered.
-
sentinel¶ A special marker object guaranteed not to exists in the original mapping, used to mark deleted keys.
-
__init__(mapping, *args, **kwargs)¶ Initialize a new context manager to replace the specified elements of the given mapping.
Positional arguments represent mappings that contain keys and values to replace or add, each one in a format that would be accepted by
dict.update.Keyword arguments are individual keys to update.
-
chain(*args, **kwargs)¶ Create a chained
mapping_contextwith the same mapping class andsentinelobject as this mapping.This method allows the example in the class docs to be rewritten as:
d = {'a': 1, 'b': 2} print(d) with mapping_context(d, b=0, c=3) as mc: print(d) with mc.chain(b=1).delete('a'): print(d) print(d) print(d)
Returns a new
mapping_context.
-
delete(*keys)¶ Remove all the keys named in
keysfrom the mapping, but keep a record of them to be restored on exit.Return the context manager itself.
-
getfunc(key)¶ A customizable function to get a single element of the mapping.
If key is not present, this function must return
sentinel.The default implementation works for most Python builtin mapping types that support a
getmethod.
-
setfunc(key, value)¶ A customizable function to set a single element of the mapping.
If value is
sentinel, the element should be deleted.The default implementation works for most Python builtin mapping types that support
__delitem__and__setitem__methods.
-
-
class
haggis.mapping.Namespace(*args, **kwargs)¶ A simple namespace object.
The class is mutable. It implements containment checks. It can be converted to a dictionary using
vars. That being said, it supports a dictionary-like interface for elements whose names are not valid python identifiers, or are shadowed by descriptors.This class originated with
argparse.Namespaceandtypes.SimpleNamespace.-
__getitem__(key)¶ Retrieve an item directly from the dictionary.
Useful for items whose names are not valid python identifiers.
Parameters: key – The key of the object to retreive. Does not have to be a string. Returns: The value mapped to the specified key. Raises an error if the key is not found. Return type: object
-
__init__(*args, **kwargs)¶ Create a new namespace with the specified named arguments.
Key-value pairs in each iterable of args are added in order, followed by the mapping kwargs.
-
items()¶ An iterator over the items in this namepace’s mapping.
-
override(**kwargs)¶ Returns a context manager that can be used to temporarily set attributes in this namespace.
The context manager has a delete method that allows values to be removed as well. The method accepts any number of attribute names to delete and returns the context manager, so it can be used in a The with statement block directly. Missing key names are ignored.
The context manager is a modified version of
mapping_context, so it also has achainmethod.All values will be reset to their original values when the manager exits. All context managers returned by this method operate on the same object, so their effects are cumulative.
Sample usage:
n = Namespace(a=1, b=2) print(n) with n.override(b=0, c=3): print(n) with n.override(b=1).delete('a'): print(n) print(n) print(n)
Will result in:
Namespace(a=1, b=2) Namespace(a=1, b=0, c=3) Namespace(b=1, c=3) Namespace(b=0, c=3, a=1) Namespace(b=2, a=1)
-
setdefault(key, value)¶ dict-likesetdefaultoperation on the namespace’s mapping.
-
-
haggis.mapping.option_lookup(name, mapping, option, key_func=None, value_func=None, err_type=<class 'ValueError'>, key_err=<class 'KeyError'>)¶ Perform a lookup of an option in a mapping whose keys represent the valid options.
If an invalid option is selected, it an err_type error is raised (
ValueErrorby default).Parameters: - name (str) – The name of the mapping to display if an error occurs. If the option is a function argument, the name of the argument is a good name choice.
- mapping (mapping) – The mapping to perform a the lookup in.
- option (object) – The key to look up in mapping.
- key_func (callable or None) – The transformation to apply to option to obtain the actual
key to look up. If
None(the default), no transformation is done. A common choice for this argument isstr.casefoldorstr.lower, for case-insensitive string keys. - value_func (callable or None) –
The transformation to apply to the value that is found. If
None(the default), no transformation is done. If supplied, must be a callable that accepts three arguments:optionkey:optiontransformed bykey_funcvalue: The raw value retreived from the dictionary.
- err_type (type) – The type of the
Exceptionto raise. Default isValueError. - key_err (type or tuple[type]) – The type of error expected from a failed lookup in mapping.
If multiple types are to be expected, a
tupleof types may be supplied. Defaults toKeyError.
-
class
haggis.mapping.RecursiveDict(*args, key_type=<class 'str'>, value_type=None, **kwargs)¶ Mapping that allows recursive lookup of keys.
Lookup can be controlled by specifying a key type and/or a value type. A value suitable for recursion that is not found as a key raises a
KeyError, while a value of the wrong type raises aTypeError. Requesting a key of the wrong type raises aTypeErroras well.Only lookup operations are different from
dict:__getitem__,setdefaultandget.popandpopitemare not modified. Full control is provided through the unaltered setter operations.Here is an example of how
value_typeaffects the lookup:d = RecursiveDict({'a': 1, 'b': 'a'}) print(d.setdefault('d', 'c')) # Prints "c"
vs:
d = RecursiveDict({'a': 1, 'b': 'a'}, value_type=int) print(d.setdefault('d', 'c')) # Raises "KeyError: 'c'"
-
key_type¶ A class object indicating the type that may be used as a key.
Noneindicates “any”. The default isstr. Values of this type indicate recursive lookup.
-
value_type¶ A class object indicating the type that may be used as a value.
None, the default, indicates “any” type.
-
__getitem__(key)¶ Recursively fetch an item from this dictionary.
-
__init__(*args, key_type=<class 'str'>, value_type=None, **kwargs)¶ Construct a new mapping with the specified key and value types.
All normal
dictconstructor arguments are accepted.key_type and value_type may be classes, tuples of classes, or
None. The latter case is equivalent to “anything goes”. The dictionary will accept keys and values of the wrong type, but will raise an error on lookup, so it is best to leave either key_type or value_type asNone.If both types are constrained and there is overlap between them, key_type always takes precedence: a value that can be a key_type is always looked up as a key. Only when the lookup fails is the value returned.
If key_type is constrained, but value_type is not, lookup continues until a
KeyErroris raised or a non-key_type value is encountered. Similarly, if only value_type is constrained, lookup continues until aKeyErroris raised or a value of the requested type is found.There is no constraint on either (both are None), recursion will stop only when a value is not present in the dictionary as a key.
-
final_key(key)¶ In a recursive reference, retreive the final key that actually contains the value mapping.
For example, given:
x = RecursiveDict(key_type=str, value_type=int) x['a'] = 'b' x['b'] = 'c' x['c'] = 1
The result of
final_keyon any of the keys defined above would be'c'.If the final key does not contain a value, it will still be returned. This means that if the dictionary above were to have
x['c'] = 'd'(a broken recursion),final_keywould return'c'regardless.Passing in a missing key will raise a
KeyErroras usual.
-
get(key, default=None)¶ Retrieve a fully dereferenced value for key if present, or default if not.
default gets dereferenced if the key is not present.
-
setdefault(key, default=None)¶ Set the key to the specified value if not found, return the value for the key.
The default value is set exactly as specified, but the return value is dereferenced.
-
-
haggis.mapping.setdefaults(mapping, *args, **kwargs)¶ Update missing keys in this mapping based on supplied iterables and mappings.
This is similar to
dict.update, except that only missing keys are added.Parameters: - mapping – The dictionary to update. If the type does not have a setdefault method, the udpate will default to using __contains__ and __setitem__ directly.
- *args – Each positional arguments may be a mapping or an iterable of two-element iterables. Iterables are applied in order. Only the first instance of a duplicated key is ever considered.
- **kwargs – Any additional keywords to insert. These are applied after the iterables, if any.
math module¶
Math utility functions that are otherwise uncategorized.
-
haggis.math.ang_diff_abs(theta1, theta2, full=6.283185307179586)¶ Find the absolute value of the minimum angular difference from theta1 to theta2, normalized to
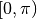 .
.The minimum absolute difference is the smallest angle to get from theta1 to theta2 going in either direction, normalized to be in the range
.The return value can be computed without branching as
ang_diff_abs = abs(ang_diff_min(theta1, theta2, full))
Inputs can be scalars or arrays. Arrays must broadcast together.
Parameters: - theta1 (array-like) – The start angle or angles, in radians.
- theta2 (array-like) – The end angle or angles, in radians.
- full (float) – The period of a full circle. Defaults to
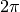 . Use 360
for data in degrees, 400 for gradians, 6400 for mils, etc.
. Use 360
for data in degrees, 400 for gradians, 6400 for mils, etc.
Returns: An array containing the broadcasted minimum absolute normalized difference of the two inputs.
Return type: numpy.ndarray
-
haggis.math.ang_diff_min(theta1, theta2, full=6.283185307179586)¶ Find the angular difference from theta1 to theta2, with the minimum absolute value normalized to
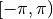 .
.The positive difference is the angle going in the positive direction from theta1 to theta2, normalized to be in the range
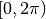 . The negative difference is the angle going in
the negative direction. This function returns the smaller of the
two by absolute value.
. The negative difference is the angle going in
the negative direction. This function returns the smaller of the
two by absolute value.The return value can be computed without branching by rotating by half a circle before applying the moduli, then rotating back:
ang_diff_min = fmod(fmod(theta2 - theta1 + 0.5 * full, full) + full, full) - 0.5 * full
Inputs can be scalars or arrays. Arrays must broadcast together.
Parameters: - theta1 (array-like) – The start angle or angles, in radians.
- theta2 (array-like) – The end angle or angles, in radians.
- full (float) – The period of a full circle. Defaults to . Use 360
for data in degrees, 400 for gradians, 6400 for mils, etc.
Returns: An array containing the broadcasted sign-preserving normalized difference of the two inputs with the smallest absolute value.
Return type: numpy.ndarray
-
haggis.math.ang_diff_pos(theta1, theta2, full=6.283185307179586)¶ Find the positive angular difference from theta1 to theta2, normalized to
.The positive difference is the angle going in the positive direction from theta1 to theta2, normalized to be in the range
.The return value can be computed without branching as
ang_diff_pos = fmod(fmod(theta2 - theta1, full) + full, full)
Inputs can be scalars or arrays. Arrays must broadcast together.
Parameters: - theta1 (array-like) – The start angle or angles, in radians.
- theta2 (array-like) – The end angle or angles, in radians.
- full (float) – The period of a full circle. Defaults to . Use 360
for data in degrees, 400 for gradians, 6400 for mils, etc.
Returns: An array containing the broadcasted positive normalized difference of the two inputs.
Return type: numpy.ndarray
-
haggis.math.count_divisors(n)¶ Counts the divisors of natural number n, including 1 and itself.
For example,
28has divisors1, 2, 4, 7, 14, 28, socount_divisors(28) == 7.
-
haggis.math.ellipse(*args, num_points=1000.0, **kwargs)¶ -
haggis.math.ellipse(a, [b=0, ]c, d, e, f, *, numPoints=1e3)
-
haggis.math.ellipse(a, b, h, k, *, theta=0, numPoints=1e3)
Return x-y arrays for an ellipse in one of two standard forms.
The equations are either the quadratic form,
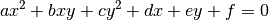
or the simplified form,
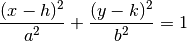
The first form allows for rotated ellipses through the
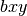 coupling term. The second form allows it through the explicit
(optional) angle parameter theta, specified in radians
counterclockwise about
coupling term. The second form allows it through the explicit
(optional) angle parameter theta, specified in radians
counterclockwise about (h, k).The number of points is specified by numPoints. Points are evenly distributed by angle, not by arc-length (unless the ellipse is a circle). The default number of points is 1000.
Returns: - x (numpy.ndarray) – Array of num_points x-coordinates.
- y (numpy.ndarray) – Array of num_points y-coordinates.
Notes
This code is loosely based on my Stack Overflow answer: http://stackoverflow.com/a/41231100/2988730, which is in turn loosely based on the forum post at http://www.sosmath.com/CBB/viewtopic.php?t=17029
-
-
haggis.math.first_primes(n)¶ Generate a set with the first n prime numbers.
This is a toy method that should probably not be used for large prime numbers. Instead of actively discarding all multiples of found primes, it checks new candidates against each element of the current set of primes.
Parameters: n (int) – Returns: primes Return type: set
-
haggis.math.full_width_half_max(x, y, factor=0.5, baseline=0.0, interp='linear', *, return_points=False)¶ Compute the full-width, half-max metric for a dataset.
The full-width half-max is the distance between where the data rises to half of the maximum for the last time before the max itself and where it falls below half of the maximum for the first time above the maximum.
The actual fraction of the maximum that is used can be adjusted with factor (which defaults to 0.5). factor can be a number or the string
'sigma', in which case it will be set to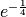 , the height of a Gaussian with unit
amplitude one standard devition away from the mean. A fixed non-zero
baseline can also be provided so that it does not have to be
subtracted from y before being passed in.
, the height of a Gaussian with unit
amplitude one standard devition away from the mean. A fixed non-zero
baseline can also be provided so that it does not have to be
subtracted from y before being passed in.Since the actual y array is unlikely to contain the exact half-max value, an interpolation can be done. Currently, the following interpolation methods are supported:
'linear': linear interpolation betweent the x- and y-values surrouding the actual half-max point.'nearest': nearest neighbor, i.e., use the x-value of the y-value that is closest to the half-max.
Normally, a single scalar is returned. If return_points is
True, however, two two-element tuples are returned as the second and third argument. Each tuple will contain an x-y pair of the intersection coordinates used to approximate the main return value. The first tuple will be for the left (rising) edge and the second will be for the right (trailing) edge.
-
haggis.math.primes_up_to(n)¶ Generate a set containing all the primes less than or equal to n.
n must be a number that represents an array size that can exist in memory. The implementation uses an extremely unoptimized version of the sieve of Eratosthenes.
Parameters: n (int) – The largest number to generate primes up to (exclusive). If you want an inclusive range, add 1 to this input. Returns: primes – A set of all the primes less than n. Return type: set
-
haggis.math.real_divide(a, b, zero=0, out=None)¶ Divide real numbers, where the second may be zero.
Parameters: - a (array-like) – The divisor.
- b (array-like) – The dividend
- zero – The value to place in locations where b is zero.
- out (array-like or None) – An array of a suitable type and size to hold the result. If None, a new output array is allocated.
Returns: The result of applying
numpy.true_divideto a and b, except that elements corresponding to zeros in b are set to zero instead of actually being computed.Return type: numpy.ndarray
-
haggis.math.rms(arr, axis=None, bias=0, weights=None, ddof=0, out=None)¶ Comute the root-mean-square (RMS) of an array about an arbitrary bias.
Parameters: - arr (array-like) – The input array.
- axis (int or tuple or None, optional) – The axis or axes to compute the RMS along. The average of the squares will be taken along this axis or axes. None (the default) indicates the entire raveled array.
- bias (array-like, optional) – The offset about which to compute the RMS. The default is zero
for standard RMS. The bias must broadcast to arr. Setting
bias=numpy.mean(arr, axis=axis, keepdims=True)is equivalent to computingnumpy.std(arr, axis=axis). - weights (array-like, optional) – The weights to apply in the mean portion. Similar behavior to
numpy.average. Assumed to be all ones if omitted. If axis is None, must broadcast to arr. Otherwise, must be the same shape as either arr[axis] or arr. - ddof (scalar, optional) – The degrees of freedom to subtract from the denominator. Defaults to zero.
- out (numpy.ndarray or None, optional) – The array to output results into, if not None. Use carefully, as all intermediate calculations will be placed into this array: a square, a mean and a square root. Using an output of an inappropriate type may lead to errors. The default is None.
Returns: rms – The RMS of arr about bias along axis.
Return type: numpy.ndarray
-
haggis.math.round_sig(x, n)¶ Round the number x to n significant figures.
-
haggis.math.segment_distance(p, p1, p2, axis=None, return_t=False, segment=True)¶ Find the distance between an N-dimensional point and a line or line segment.
The distance from a point to a line in N dimensions is the length of a normal dropped to the line. Using the fact that the dot product of orthogonal vectors is we can find the point
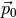 on the line that corresponds to this location.
on the line that corresponds to this location.First, parametrize the points on the line through parameter
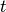 as
as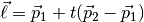
Then set up the equation with dot-products and solve for
: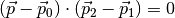
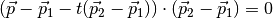
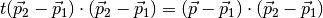
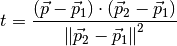
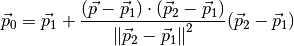
The value of
represents the location of
in relationship to  and
and  : values
in the range
: values
in the range ![[0, 1]](_images/math/02b99e25ae92d555c285768eb92a199abd3cf9e2.png) are on the line segment, negative
values are on the side closer to , and values
greater than one are on the side of the line closer to
.
are on the line segment, negative
values are on the side closer to , and values
greater than one are on the side of the line closer to
.The value of
at the closest approach can be returned by
setting return_t=True. The value returned in this case applies to the entire line, even ifsegment == Trueand the closest point is one of the endpoints of the line segment.Parameters: - p (array-like) – The target point. Must broadscast to p1 and p2.
- p1 (array-like) – The start of the line segment. Must broadcast to the same shape as p and p2.
- p2 (array-like) – The end of the line segment. Must broadcast to the same shape as p and p1.
- axis (int or None) – The axis corresponding to the point vectors in the broadcasted arrays. If None, all point arrays are raveled.
- return_t (bool) – If True, return an additional value indicating the parameter
at the distance of closest approach along the line.
This will be the same regargless of segment.
- segment (bool) – If True, find the nearest point on the line segment bounded by p1 and p2 rather than the line passing between them.
Returns: dist (float or ~numpy.ndarray) – Distance from p to the line or line segment passing through p1 and p2. The shape of the result is the broadcasted shape of the inputs, collapsed along axis.
Scalar if axis is None or the inputs are all one-dimensional.
t (float or ~numpy.ndarray) – An array of the same shape as dist containing the value of parameter
for each line. The parameter is the
location of the normal from p to the line passing through
p1 and p2, regardless if the distance is to the line
segment or the line.Returned only if return_t is set.
-
haggis.math.threshold(arr, thresh=3, type='std', direction='le')¶ Apply a threshold to an array (usually an image).
Parameters: - arr (array-like) – The array to threshold.
- direction (str) –
Which direction is considered passing:
'le'or'<=': Elements of arr <= the threshold are marked True.'lt'or'<': Elements of arr < the threshold are marked True.'ge'or'>=': Elements of arr >= the threshold are marked True.'gt'or'>': Elements of arr > the threshold are marked True.
The default is
'le'. - thresh (array-like, optional) – The threshold value to apply. Must broadcast to the shape of the
array. The exact meaning of the value is determined by type.
The default is
3(for 3-sigma thresholding). - type (str, optional) –
The type of threshold to use:
'std': Mean plus threshold times standard deviation.'iqr': Median plus threshold times interqartile range.'rms': threshold times the root-mean square.None,'','raw': Use threshold as-is.
The default is ‘std’.
Returns: A boolean array of the same size and shape as arr, containing a mask indicating which elements pass threshold.
Return type: numpy.ndarray
mpl_util module¶
Utilities for handling MatPlotLib figures, only available when the
[plot] extra is installed.
If matplotlib is not found at import time, this module will have only
a plot_enabled attribute, which will be False. If
matplotlib is found, on the other hand, plot_enabled will
be True, and all the other documented functions and attributes
of the module will be present.
-
haggis.mpl_util.plot_enabled¶ A boolean value indicating whether the
[plot]extra has been installed. IfFalse, the API will be severely limited.
-
haggis.mpl_util.figure_context(*args, **kwargs)¶ A context manager that automatically closes the figure that it opens.
Inspired by https://github.com/matplotlib/matplotlib/issues/5218/#issue-110729876
-
haggis.mpl_util.save_figure(fig, file=None, size=None, **kwargs)¶ Save the figure as an image using
matplotlib.figure.Figure.savefig.The main value of this method is that it automatically saves to memory via a
BytesIOobject if a file is not specified.Parameters: - fig – The figure to save
- file (str, file-like, or None) – If not
None, there is no return value. IfNone,BytesIOcontaining the image will be returned. The output will be rewound to the start in that case. The default isNone. - size (sequence[int]) – The size of the figure in inches, as a 2-element sequence
(w, h). If either of the elements isNone, the aspect ratio of the figure will be preserved. Even if only the width is specified, size must be a sequence.
All other arguments are passed through directly to
savefig. Some common options include:- dpi :
- The resolution of the output image in dots-per-inch.
- format :
- The output format.
'png','svg','pdf'have good support. If not supplied, the default is explicitly set to'png'. - frameon :
- Whether of nor the figure background should be rendered.
Defaults to
Trueif not supplied. - transparent :
- Whether or not the axes background should be rendered as transparent. Defaults to the inverse value of frameon if not supplied.
- bbox_inches :
- The portion of the figure to save. If
'tight', try to use the entire figure. If unset, defaults to'tight'. - pad_inches :
- The amount of padding to add around the figure when
bbox_inches is
'tight'.
-
haggis.mpl_util.set_figure_size(fig, w=None, h=None)¶ Set the size of a figure in inches, optionally preserving the aspect ratio.
If either or the size arguments is
None, it will be scaled to preserve the current aspect ratio. If both areNone, the size is not set at all.
-
haggis.mpl_util.set_labels(artists, labels)¶ Assign a separate label to each artist in the iterable.
Useful in labelling each column separately when plotting a multi-column array. For example:
from matplotlib import pyplot as plt import numpy as np x = np.arange(5) y = np.random.ranint(10, size=(5, 3)) fig, ax = plt.subplots() set_labels(ax.plot(x, y), 'ABC')
Based on https://stackoverflow.com/a/64780035/2988730.
Parameters: - artists – Iterable of artists. Any extra entries are silently ignored (not labeled).
- labels – Iterable of strings. Any extra labels are silently dropped.
-
haggis.mpl_util.show_extents(img, x=None, y=None, ax=None, **kwargs)¶ Display an image with the correct x- and y- coordinates, adjusted to pixel centers.
This function is a wrapper around
imshow. Normally,imshowwill scale the axes limits to the outer edges of the image when given anextentargument. However, it is generally more accurate to set the centers of the pixels.Parameters: - img – The image to display.
- x (array-like, optional) –
The x-coordinates of the pixels. Only the first and last coordinate are ever used, so it is safe to pass in any sequence of two numbers.
x[0]is the intended x-coordinate of the center of the leftmost column of the image, whilex[-1]is the x-coordinate of the center of the rightmost column.Defaults to
[0, img.shape[1] - 1]. - y (array-like, optional) –
The y-coordinates of the pixels. Only the first and last coordinate are ever used, so it is safe to pass in any sequence of two numbers.
y[0]is the intended y-coordinate of the center of the topmost row of the image, whiley[-1]is the y-coordinate of the center of the bottommost column.Defaults to
[0, img.shape[0] - 1]. - ax (matplotlib.axes.Axes, optional) – The axes to plot on. If not supplied, a new figure and axes are created.
- **kwargs – All remaining arguments are passed through to
imshow. If an explicitextentis passed in,xandywill be ignored.
Returns: image – The image object created by
imshow.Return type:
-
haggis.mpl_util.semilogx_base(axes, *args, basex=2.718281828459045, labelx='e', **kwargs)¶ Create a semilogx plot with a custom base.
The default is to use base e.
This is a convenience wrapper for
semilogxwhich setsbasexand adds a formatter with a custom label.Parameters: - axes (matplotlib.axes.Axes) – The axes to plot on.
- *args – Normal positional arguments to
semilogx. - basex (float, optional) – Base of the x-axis log-scale. The default is numpy.e.
- labelx (str, optional) – The label to use to show the log base for tick marks in the
x-axis. The default is
'e'. - **kwargs – Normal keyword arguments to
semilogx.
Returns: Objects representing the plotted data.
Return type: list of
Line2D
-
haggis.mpl_util.semilogy_base(axes, *args, basey=2.718281828459045, labely='e', **kwargs)¶ Create a semilogy plot with a custom base.
The default is to use base e.
This is a convenience wrapper for
semilogywhich setsbaseyand adds a formatter with a custom label.Parameters: - axes (matplotlib.axes.Axes) – The axes to plot on.
- *args – Normal positional arguments to
semilogy. - basey (float, optional) – Base of the y-axis log-scale. The default is numpy.e.
- labely (str, optional) – The label to use to show the log base for tick marks in the
y-axis. The default is
'e'. - **kwargs – Normal keyword arguments to
semilogy.
Returns: Objects representing the plotted data.
Return type: list of
Line2D
-
haggis.mpl_util.loglog_base(axes, *args, basex=2.718281828459045, basey=2.718281828459045, labelx='e', labely='e', **kwargs)¶ Create a log-log plot with a custom base.
The default is to use base e.
This is a convenience wrapper for
loglogwhich setsbasex,basey, and adds a formatter with a custom label.Parameters: - axes (matplotlib.axes.Axes) – The axes to plot on.
- *args – Normal positional arguments to
loglog. - basex (float, optional) – Base of the x-axis log-scale. The default is numpy.e.
- basey (float, optional) – Base of the y-axis log-scale. The default is numpy.e.
- labelx (str, optional) – The label to use to show the log base for tick marks in the
x-axis. The default is
'e'. - labely (str, optional) – The label to use to show the log base for tick marks in the
y-axis. The default is
'e'. - **kwargs – Normal keyword arguments to
loglog.
Returns: Objects representing the plotted data.
Return type: list of
Line2D
npy_util module¶
Utilities for manipulating non-computational aspects of numpy arrays.
Mathematical computations belong in haggis.math.
-
haggis.npy_util.find_peaks(arr, n_peaks=None, mode='value', return_values=False)¶ Find the locations of the n_peaks tallest or leftmost (unfiltered) local maxima of arr.
When
mode=='value', the first peak is located atarr.argmax(). The second peak is the maximum value among the numbers that are not monotonically non-increasing away from the first peak. Successive peaks are returned from remaining portions of the array.For a plateau with multiple equal peak elements, only the first is returned. Similarly, if multiple peaks with the same values are found, they will be retreived in order of increasing index.
Parameters: - arr (array_like) – The data to search through. Expected to be 1D. Larger dimensions are raveled to avoid the problem of different numbers of results along a given axis.
- n_peaks (int or None) – The number of peaks to search for. None or negative searches for all available peaks. If n_peaks local maxima are not found, the result will be shorter than requested.
- mode (str) –
One of {
'value','index'} (case insensitive):'value': Return up to the first n_peaks tallest peaks, regardless of location.'index': Return up to the first n_peaks local maxima, traversing the array from left to right, regardless of peak height.
- return_values (bool) – Return a second array containing the maximum values at each
location. Convenience for
arr[find_peaks(arr, ...)].
Returns: - peak_indices (numpy.ndarray[int]) – Locations of up to n_peaks local maxima. May be shorter than n_peaks if there are insufficient local maxima in the data.
- peak_values (numpy.ndarray) – Elements of arr at peak_indices.
Notes
To get peaks in reverse order with
mode='index', reverse the input:arr[::-1].To get peaks sorted from left to right with
mode='value', sort the results.
-
haggis.npy_util.isolate_dtype(dtype, char='O')¶ Create a new dtype that only contains the fields and subfields of dtype matching primitive type given by letter char.
The new dtype will be flat with N fields containing the offsets to the original elements of interest. It will have the same itemsize as dtype. Field names are not preserved.
Parameters: - dtype (numpy.dtype) – Data type to parse out
- char (str[1]) – Primitive type character code to search for
Returns: isolated – A dtype containing offsets to all instances of char in dtype.
Return type: dtype
-
haggis.npy_util.iterate_dtype(arr, iterate_elements=False, yield_key=False)¶ Generate each primitive sub-array of a complex datatype.
The generator yields the array for each builtin dtype. The leading dimensions of each yielded array are arr.shape the trailing dimensions are determined by iterate_elements and the shapes present in each sub-dtype. Currently, only depth-first traversal is supported.
An optional field key can be yielded as well, if yield_key is set. The key is a dot-separated string enumerating the visited fields. If iterate_elements is specified, it will contain bracketed indices as well. See the Examples section for more information, including a sample of the key format.
Parameters: Examples
Create a complex dtype and an array of zeros:
>>> dt0 = np.dtype([('a', np.float32), ('b', np.int32, 2)]) >>> dt = np.dtype([('x', np.bool_), ('y', dt0, 3)]) >>> arr = np.zeros((3, 3), dt)
When iterating without elements, the genrator does not descend into each sub-dtype consisting of primitives:
>>> for a, k in iterate_dtype(arr, yield_key=True): ... print(k, a.dtype, a.shape) x bool (3, 3) y.a float32 (3, 3, 3) y.b int32 (3, 3, 3, 2)
When iterate_elements is set, the generator descends into the elements of each sub-dtype, even if they are primitive:
>>> for a, k in iterate_dtype(arr, iterate_elements=True, yield_key=True): ... print(k, a.dtype, a.shape) x bool (3, 3) y[0].a float32 (3, 3) y[0].b[0] int32 (3, 3) y[0].b[1]int32 (3, 3) y[1].a float32 (3, 3) y[1].b[0] int32 (3, 3) y[1].b[1] int32 (3, 3) y[2].a float32 (3, 3) y[2].b[0] int32 (3, 3) y[2].b[1] int32 (3, 3)
-
haggis.npy_util.map_array(map, arr, value=None, default=<haggis.SentinelType object>)¶ Convert the elements of a numpy array using a mapping.
The implementation uses looping to interface between the python and numpy datasets, but is as efficient as possible under the circumstaces. Intended for mapping a small number of arbitrary labels to some alternative value.
Parameters: - map (Mapping) – The mapping to apply. Any object with a get method that supports default values is accepted.
- arr (array-like) – The array to convert.
- value (callable, optional) – A function to apply to the dictionary values before placing in the output array. The default is a no-op.
- default – The value to use for array elements not in mapping. The default is to raise a KeyError. None is interpreted as a valid default.
Returns: mapped_array – An array of the same shape as arr, with elements transformed according to the mapping.
Return type: array-like
-
haggis.npy_util.mask2runs(mask, return_lengths=False, return_borders=False)¶ Find the runs in a boolean mask.
Parameters: - mask (array-like) – Boolean mask. If not boolean, will be cast to bool.
- return_lengths (bool, optional) – Whether or not to return an array of lengths for each run.
- return_borders (bool, optional) – Whether or not to return an array of dtype np.int8 containing 1 at each run start and -1 past run ends. The default is False.
Returns: - regions (numpy.ndarray (N, 2)) – Array of indices for each run. First column is the location of the run start, second column is past the run end.
- lengths (numpy.ndarray (N)) – The length of each run. This is effectively
regions[:, 1] - regions[:, 0]. Only returned if return_lengths is True. - borders (numpy.ndarray (mask.size + 1)) – Array of
numpy.int8containing 1 at each run start, -1 past each run end, and zero elsewhere. Only returned if return_borders is True. Extends one element past the end of mask.np.cumsum(borders).view(bool)[:-1]is equivalent to mask.
-
haggis.npy_util.masked_index(index, mask)¶ Convert N-dimensional index into its corresponding location in the masked array, if it is in the masked portion.
Given an array
x, of the same size as mask, determine the position ofx[index]inx[mask]. If index is not in the masked portion, the corressponding output is set to-1.Parameters: - index (tuple) – The index or indices into the unmasked multi-dimensional array.
A non-tuple (scalar or array) index may be used for 1D masks,
will be wrapped in a tuple internally to avoid ambiguity. The
number of elements in the tuple must match
mask.ndim, and all elements must all broadcast together. - mask (array-like[bool]) – A boolean mask to determine the indices of the array.
Non-boolean mask arrays will be interpreted as booleans, as
though with
mask.astype(bool). Scalar arrays will be interpreted as one-element arrays, so scalar indexing allowed.
Returns: masked_index – If index corresponds to a True element of mask, return its position in the masked result. Otherwise, return None.
Return type: - index (tuple) – The index or indices into the unmasked multi-dimensional array.
A non-tuple (scalar or array) index may be used for 1D masks,
will be wrapped in a tuple internally to avoid ambiguity. The
number of elements in the tuple must match
-
haggis.npy_util.prune_mask(mask, min_length=None, max_length=None, filter_func=None, return_runs=False, return_lengths=False, return_borders=False)¶ Prune the runs in mask to conform to some criteria.
Parameters: - mask (array-like) – Boolean mask. If not boolean, will be cast to bool.
- min_length (int, optional) – Runs shorter than this will be removed. Ignored if None.
- max_length (int, optional) – Runs longer than this will be removed. Ignored if None.
- filter_func (callable, optional) – Function that accepts an Nx2 array of runs, as from mask2runs, and returns an N-length boolean mask. True elements in the result will be retained, while False elements will be removed. Called after applying min_length and max_length constraints, if those are requested.
- return_runs (bool, optional) – Whether or not to return an Nx2 array of indices for the start (inclusive) and end (exclusive), of each run within the mask.
- return_lengths (bool, optional) – Whether or not to return an array of lengths for each retained run.
- return_borders (bool, optional) – Whether or not to return an array of dtype np.int8 containing 1 at each run start and -1 past run ends.
Returns: - pruned (numpy.ndarray[bool]) – Mask with any runs shorter than min_length and longer than max_length removed and filter_func applied to the remaining runs.
- runs (numpy.ndarray) – Nx2 array of remaining run indices, returned if return_runs is set. Same format as the result of mask2runs. Start index in the first column is inclusive, stop index in the second column is exclusive.
- lengths (numpy.ndarray) – N-element array of lengths of remaining runs, returned if return_lengths is set.
- borders (numpy.ndarray[numpy.int8]) – Array of the same size as mask containing 1 at the start of each run and -1 past the end, returned if return_borders is set. The sum of this array is the mask.
-
haggis.npy_util.replace_field(in_type, out_type, *fields, name=None)¶ Create a dtype that will allow viewing a subset of the fields of in_type with a different structure.
This function preserves the names, types, and offsets of all the unmodified fields. The replacement type will cover the entirety of the named fields, regardless of whether the underlying fields are contiguous or not.
If the size of the replaced block is a multiple of out_type.itemsize other than one, the output type will be an array. The multiple must be an integer.
Parameters: - in_type (numpy.dtype) – Datatype to transform.
- out_type (numpy.dtype) – Primitive types may be provided as the equivalent string or class object.
- *fields (str) – Names of the fields to transfrom. An empty fields means that all of them are to be replaced. A new field is generated as a contiguous block whose size must be a multiple of out_type.itemsize. All elements must be valid field names in in_type.
- name (str, optional) – The name of the replacement field. By default, this is just the concatenation of fields, respecting CamelCase and snake_case conventions in transitions.
Returns: dtype – Dtype with the named fields replaced by a scalar or array of out_type. All other fields remain the same.
Return type: numpy.dtype
Examples
A simple case:
>>> inner = np.dtype([('Roll', np.float32), ... ('Pitch', np.float32), ... ('Yaw', np.float32)]) >>> outer = np.dtype([('Position', np.float32, 3), ... ('Attitude', inner)]) >>> replace_field(outer, np.float32, 'Attitude') dtype([('Position', '<f4', (3,)), ('Attitude', '<f4', (3,))])
To modify nested custom types, call this function recursively:
>>> replace_field(outer, replace_field(inner, np.float32), 'Attitude') dtype([('Position', '<f4', (3,)), ('Attitude', [('RollPitchYaw', '<f4', (3,))])])
-
haggis.npy_util.runs2mask(runs, n=None)¶ Convert an Nx2 array of run indices, such as the return of
mask2runsinto a boolean mask of size n.Parameters: - runs (array-like) – A two-column array, the first column being inclusive start indices for each run, and the second being exclusive stop indices.
- n (int, optional) – The size of the mask to generate. If missing (None), the
end of the last run is assumed (
runs[-1, 1]).
Returns: mask – A boolean array of length
nwith runs set to True.Return type: numpy.ndarray
-
haggis.npy_util.unmasked_index(index, mask)¶ Convert index in a masked aray into the corresponding index in the original.
Given an array
xof the same size as mask, determine the position ofx[mask][index]in the original arrayx. Since mask may be multi-dimensional butx[mask]is always raveled, the result may be a scalar or a tuple.Parameters: - index (array-like[int]) – The index or indices into in the masked (raveled) array. Each
element must be in
[-np.count_nonzero(mask), np.count_nonzero(mask)). - mask (array-like[bool]) – A boolean mask to determine the indices of the array.
Non-boolean mask arrays will be interpreted as booleans, as
though with
mask.astype(bool). Scalar arrays will be interpreted as one-element arrays, so scalar indexing allowed.
Returns: unmasked_index – If mask is a scalar or 1D, the result is the same size and shape as index. Otherwise, it is a tuple of length
mask.ndimeach of whose elements corresponds to a dimension, and it the same size and shape as index`.Return type: - index (array-like[int]) – The index or indices into in the masked (raveled) array. Each
element must be in
numbers module¶
Various written-language related routines pertaining to numbers.
-
haggis.numbers.as_base(n, base=10, letters=True, sign=True)¶ Convert integer n to representation as base.
For bases 36 and under, digits 10 or larger can be represented by English letters in range A-Z. For larger bases, the output must be a list.
Only absolute value of the number is coverted. For string representations, a
-symbol can be prepended. Otherwise, it is the user’s responsibility to handle sign.Parameters: - n (int) – The number to represent.
- base (int) – The base of representation. Must be a positive integer. Special case of 1 is allowed.
- letters (bool, optional) – If True, represent digits larger than 9 with ASCII uppercase
letters and return a string. If
base > 36, this parameter is ignored (implicitly False). - sign (bool, optional) – Prepend a minus sign if returning a string and n is negative.
Ignored if
letters is Falseorbase > 36.
Returns: num – If
letters is Trueandbase <= 36, this is a string representation of num in base with optional sign. Otherwise, it is a list of digits from highest to lowest, ignoring sign.Return type: Notes
Inspired by https://stackoverflow.com/a/28666223/2988730
-
haggis.numbers.digit_count(n, base=10)¶ Compute the number of digits required to represent an integer in a given base, ignoring sign.
All numbers have at least one digit except zero. The sign is removed when counting digits.
Parameters: Returns: Return type: The number of digits in n when represented in base.
Notes
For string representations, count zero as a digit using:
max(digit_count(n, base), 1)
-
haggis.numbers.english(num, mode='basic', hyphens=True, one_is_a=False, format='d')¶ Convert non-negative integer into its (mostly British) English equivalent.
Integers up to 999 vigintillion (1064 - 1) are supported.
Usage is modifiable British as specced out in http://english.stackexchange.com/a/111837/207127.
Optional hyphens can be turned off by setting hyphens to
False.The more American prefix “one” is preferred when the highest power of 10 is a unit. True British usage can be enabled be setting one_is_a to
True. This will make 100 translate as “a hundred” instead of the (default) Americanized “one hundred”.Supported values for mode are:
'basic': Convert1into'one'.'ordinal': Convert1into'first'.'suffix': Convert1into'1st'. Usage rules are irrelevant with this option.
Usage of higher powers of 10 are Americanized as well:
- 106: million
- 109: billion
- 1012: trillion
- 1015: quadrillion
- etc…
format is an optional string that specifies an integer format conforming to the Python Format Specification Mini-Language (used by
string.Formatterandstr.format). The default is'd'.
-
haggis.numbers.metric_prefix(num, long=False, eng=False)¶ Return a number and the letter that represents its metric prefix.
Prefixes are recognized in powers of 103 between 10-24 and 1024. Prefixes for 10-2, 10-1, 101 and 102 are also recognized if
eng=False.Known prefixes are given in the following table:
Prefix Symbol Power of 10 yotta Y 24 zetta Z 21 exa E 18 peta P 15 tera T 12 giga G 9 mega M 6 kilo k 3 hecto h 2 deca da 1 <None> <None> 0 deci d -1 centi c -2 milli m -3 micro μ -6 nano n -9 pico p -12 femto f -15 atto a -18 zepto z -21 yocto y -24 Parameters: Returns: - num (number) – The normalized number
- prefix (str) – One of the metric prefix strings. If num is already normalized, this is an empty string.
- factor (float) – A factor such that
num * factoris the original input. Ifnumis normalized, factor is 1.0.
objects module¶
Functions for manipulating the structure of objects.
This includes things like spoofing module contents, copying classes and functions, and automatically creating properties.
-
class
haggis.objects.HiddenPropMeta¶ Creates a class with “hidden” read-only properties named in the
__hidden_properties__attribute.A hidden property is one that stores its value under a
__dict__key with the same name. This meta-class is therefore incompatible with anything that uses__slots__.This can be a single string, an iterable of strings, or an iterable of two-element tuples containing a string name and an initial value. Strings and tuples may be mixed together in an iterable. The attribute will be removed from the class body by this metaclass after it is processed.
If the class has an explicit
__init__method defined, it will be properly decorated to set the default values of the hidden properties. If an explicit__init__is not found, the implicitsuper.__init__constructor will be decorated in the same way and set as the initializer.
-
haggis.objects.copy_func(f, globals=None, name=None, module=None)¶ Creates a shallow copy of a function object, optionally replacing the object it references for its globals.
This function is useful when importing a function into another module, and having it behave as a function of the importing module:
from mod import func func = copy_func(func, globals(), module=__name__)
Parameters: - f (function) – The object to copy
- globals (dict or None) – If
None, copy the global dictionary referenced by f. A popular alternative isglobals(). - name (str or None) – The name to assign to the new function. If None, copy
f.__name__directly. - module (str or None) – The name of the module that this function belongs to. If
None, copyf.__module__directly. A popular alternative is__name__.
Notes
Based originally on https://stackoverflow.com/a/13503277/2988730, and updated in https://stackoverflow.com/a/49077211/2988730.
-
haggis.objects.copy_class(c, globals=None, module=None)¶ Creates a shallow copy of a class object, optionally replacing its module and the object its methods reference for globals.
This function is useful when importing a class into another module, and having it behave as a class of the importing module:
from mod import cls cls = copy_class(cls, globals(), __name__)
Parameters: - c (type) – The class to copy
- globals (dict or None) – If
None, copy the global dictionaries referenced by the methods unchanged. A popular alternative isglobals(). - module (str or None) – The name of the module that this class belongs to. If
None, keepc.__module__and the modules of all methods directly. A popular alternative is__name__.
Notes
This function may not work properly for classes whose metaclass does not invoke
type.newat some point in the construction process.
-
haggis.objects.getsizeof(obj, handlers=None, default=400)¶ Recursive version of
sys.getsizeoffor handling iterables and mappings.Supports automatic circular reference detection, and does not double-count repeated references. String and array types get special treatement: they are iterable, but not processed recursively because their size already includes the buffer. The following types are treated as array types:
strbytesbytearrayarray.arraynumpy.ndarray
Additional array/string-like types may be added by appending them to the module-level tuple
size_type_mapping. Numpy arrays require special treatment because they can contain references to other objects nested at arbitrarily deep levels of the datatype.References are not fully supported yet, but a custom handler can be added to
size_type_mapping. Object attributes have only rudimentary support via recursion into__dict__and__slots__(not necessarily mutually exclusive). Additional support is available via custom implementations of__sizeof__, or through custom handlers.Parameters: - obj – The object whose size is to be computed.
- handlers (None, Iterable[tuple[type, callable]], Mapping) – Mapping of types to handler functions, or list of tuples
containing type-handler pairs. Items are iterated in reverse
order, so place more specific types last. Callables must
accept the object whose elements are to be sized, and return
an iterable of the top-level elements. Any handlers speciied
through this argument supersede defaults set in
size_type_mapping. - default (int) – The default size to use for objects that do not support a
__sizeof__operation. Default:sys.getsizeof(int).
Returns: size – The size of the object and all the references it contains. This is especially useful for container types.
Return type: Notes
This recipe is inspired by Raymond Hettinger’s “Compute Memory footprint of an object and its contents” available at https://github.com/ActiveState/recipe-577504-compute-mem-footprint and https://code.activestate.com/recipes/577504/. This function was originally written at https://stackoverflow.com/a/70793151/2988730. Things I took from Raymond’s recipe after the fact:
- Making handlers iterate through the elements instead of applying the original recursion function directly.
- Using a default value.
- Accepting a mapping of extra handlers.
Things I added:
- Proper handling of strings, bytes and bytearrays
- Numpy array handler
- Global type registry
- Support for __dict__ and __slots__
-
haggis.objects.package_root(module)¶ Find the directory containing the root package in which a module is defined.
Only works for modules with a valid
__file__attribute.Parameters: module (str or ModuleType) – The module to investigate. If a name is passed in, the module must exist in sys.modules.Returns: path – The root path of the package containing the module. Return type: str
-
haggis.objects.size_type_mapping= [(<class 'collections.abc.Iterable'>, <built-in function iter>), (<class 'collections.abc.Mapping'>, <function <lambda>>), ((<class 'str'>, <class 'bytes'>, <class 'bytearray'>, <class 'array.array'>), None), (<class 'numpy.ndarray'>, <function ndarray_handler>)]¶ List mapping of types to the special processing routines required to support them with
getsizeof.Types are checked from the end of the list. The first element is
Iterable, which is the universal catchall. Later elements are more specific types. Custom types should be appended to the end.The following types are supported out of the box:
The list contains two-element tuples, as would be used to initialize a
dict. The first element can be a scalar type or tuple of types. The second element may be None, indicaing a passthrough tosys.getsizeof, or a callable accepting an object of the correct type, returning an iterable of elements in any order. The callable only needs to iterate the top-level elements.Permanently register handlers by appending the appropriate tuple to this list. Temporarily register them by using the handlers argument to
getsizeof.
-
haggis.objects.update_module(current, other, recurse=False)¶ Updates the dict of the module current with the dict of other.
Either input may be a string (full name as given by
__name__), or a module reference.All functions and classes in other whose module is other will by default be copied and reassigned to current. All other non-dunder attributes will be copied exactly. Dunder attributes will be skipped, except
__all__, which will be shallow-copied as a list.Any attributes already defined in current will be skipped. This ensures that the globals defined in new methods will be updated correctly for the new module.
If recurse is set to
True, any sub-modules of other will be copied using this method instead of referenced directly.
os module¶
Recipes for common tasks that build on the type of thing normally found
in the builtin os module.
-
haggis.os.command_line(exec=None, args=None, quote='"')¶ Reconstruct a command line based on the specified executable exec and iterable of arguments args.
exec defaults to
sys.executableand args defaults tosys.argv.
-
haggis.os.root_path(file=None)¶ Retrieve the root file system for the given file, or for the whole OS.
On Windows this will be a drive letter followed by a backslash. On most Unix variants, this will just be a slash.
-
haggis.os.filter_copy(src, dest, hook=None, *, encoding=None, strip_newlines=False)¶ Copy a file line by line with optional processing of the lines.
src and dest can be either file-like objects or strings or file descriptors. If src is file-like, it will only be copied from the current position of the cursor. If dest is file-like, it will be appended to or overwritten from the current position of the cursor. Otherwise, it will be truncated.
hook is a function that accepts a line from src and returns the modified line to write into dest. The default value of
Noneis equivalent to a pass-thru likelambda x: x. A return value ofNonemeans to print nothing to the file. This is not the same as an empty string ifstrip_newlines=True.If strip_newlines is
False(the default), the input to hook will contain the trailing newline characters. Whether or not the output does is entirely up to the implementation, but one will not be automatically appended. If strip_newlines isTrue, the input to hook will not contain the trailing newline and one will be appended to the output if the input contained one.
-
haggis.os.add_system_path(*paths, append=True, var='PATH')¶ Extends the
PATHenvironment variable with the specified sequence of additional elements.Elements are only added if they are not already present in the existing path. This function only does literal comparison and append. It does not account for environment variable expansion or anything like that.
-
haggis.os.chdir_context(path, current=None)¶ A context manager that changes the current directory using
os.chdir.The current directory is reinstated once the manager exits.
Parameters: - path (path-like or file-descriptor) – The directory to temporarily change to. Any argument that is
valid for
os.chdiris valid here. - current (path-like or file-descriptor or None) – The directory to return to once the context manager exits. If
omitted or
None, the current working directory as returned byos.getcwdis used. As with path, the argument must be valid foros.chdir.
- path (path-like or file-descriptor) – The directory to temporarily change to. Any argument that is
valid for
-
class
haggis.os.Tee(stream1, stream2)¶ An output stream that directs output to two different streams.
This class provides a
writeandflushmethods. Since it is intended to be used withsys.stdoutandsys.stderr, it also provides anisattymethod, which always returnsFalse.-
s1¶ The first stream to write to in the tee.
-
s2¶ The second stream to write to in the tee.
No checking is done on the streams, e.g., to make sure that they are opened with the same mode, etc.
Todo
Add the proper mixins/ABCs from io package.
-
close()¶ Closes either of the underlying streams that is not a TTY.
Streams with no callable
isattyattribute are closed if they have a callablecloseattribute.
-
flush()¶ Attempt to flush both teed streams.
Streams are only flushed if they have a callable
flushmethod. Closed streams will not be flushed.
-
write(string)¶ Write the output to both teed streams.
This method does not return anything.
-
-
class
haggis.os.StdoutTee(stream)¶ Tees output to
sys.stdoutand another stream.This class replaces
sys.stdoutif used as a context manager. It retains a reference to the original stream, which it replaces on exit.
-
class
haggis.os.StderrTee(stream)¶ Tees output to
sys.stderrand another stream.This class replaces
sys.stderrif used as a context manager. It retains a reference to the original stream, which it replaces on exit.
recipes module¶
Useful and mostly compact shortcuts for common operations.
Implementations based on some of the recipes provided in the Python documentation, and other sources like Stack Overflow.
-
haggis.recipes.all_combinations(sequence, start=0, stop=None)¶ Generate all combinations of a sequence with all possible lengths.
The smallest length is start, which defaults to zero. The largest is stop, which defaults to len(sequence). stop is inclusive.
To use an iterable with no
len, specify stop manually.Example:
all_combinations([1, 2, 3])
generates:
(,), (1,), (2,), (3,), (1, 2), (1, 3), (2, 3), (1, 2, 3)
-
haggis.recipes.all_nsc(iterable)¶ A non-short-circuiting version of
all.Useful for situations where the side-effects of an iterator are useful, for example when the elements are produced by a callable in a generator that also logs the
Falseelements.The default behavior
all([]) == Trueis preserved.See https://stackoverflow.com/q/1790520/2988730 for source material.
-
haggis.recipes.any_nsc(iterable)¶ A non-short-circuiting version of
any.Useful for situations where the side-effects of an iterator are useful, for example when the elements are produced by a callable in a generator that also logs the
Trueelements.The default behavior
any([]) == Falseis preserved.See https://stackoverflow.com/q/1790520/2988730 for source material.
-
class
haggis.recipes.chained_getter(spec, *args, **kwargs)¶ Create a getter function similar to
operator.attrgetterthat can traverse a chain of index and attribute lookups.The spec string is formatted very similarly to that of
operator.attrgetter, with the addition that indices may be specified as well, similarly tooperator.itemgetter.Indices can be integer, positional, or named arguments. To specify a positional index, simply leave the brackets blank and supply the value in *args. To specify a named argument, place the name in brackets and add the corresponding value to **kwargs.
Parameters: - spec (str) – A format string that determines a series of attribute and index lookups to perform.
- *args – Positional arguments to fill in for empty bracket placeholders in the spec. The index is computed from the number of empty brackets only.
- **kwargs – Named arguments to fill in for brackets with key identifiers in spec.
Returns: - A callable that can look up multiple nested attributes and indices,
- similarly to, but more generally than
operator.attrgetter - and
operator.itemgetter.
Examples
The following will create a getter for the first element of attribute
a:chained_getter('a[0]')
Attributes may be chained:
chained_getter('a.b[1].c.d')
For non-numerical indices, supply the index object as a positional argument by leaving empty brackets. When called on object
x, the following will look upx.a.b['key']:chained_getter('a.b[]', 'key')
Named arguments can also be used by placing an identifier name in the brackets and adding the corresponding value to
kwargs:chained_getter('a.b[name]', name='key')
Indices can be chained just like attributes, and numbers can be specified as any other object. Named and positional indices can be mixed. Position index is computed from the number of empty brackets found. The following will index
[3]['key']['index'][4][5][6]:chained_getter('[][name1][][][name2][name3]', 3, 'index', 4, name1='key', name2=5, name3=6)
-
__call__(target)¶ Extract nested attributes from target object.
-
__init__(spec, *args, **kwargs)¶ Initialize a getter for the specified parameters.
-
class
haggis.recipes.CloseableMixin¶ Mixin for simple context management for objects with a
closemethod.-
__exit__(*args)¶ Closes the object, returns None.
-
close()¶ Default no-op implementation of close.
Child classes are always expected to provide the correct behavior.
-
-
haggis.recipes.consume(iterator, n=None)¶ Consume an iterator entirely, or advance n steps ahead.
This function is based pretty much exactly on the similarly named recipe in the documentation at https://docs.python.org/3/library/itertools.html#itertools-recipes
-
haggis.recipes.grouper(iterable, n, tail=True, fillvalue=None)¶ Gather an iterable into chunks or blocks of fixed length.
Based on
grouperfrom Itertools Recipes. The main difference is that this implementation allows the final chunk to contain fewer elements. This version also returns lazy iterables for the inner chunks, unlike thegrouperrecipe which returns chunks.By default, the iterator assumes that all of the elements of a group have been consumed by the caller. If this is not the case, the next group will start with the un-consumed segment. An easy way to guarantee proper consumption is to use
consume.Inspired by https://stackoverflow.com/a/23926929/2988730.
Parameters: - iterable (iterable) – The iterable to split.
- n (int) – The size of the chunks to split into.
- tail (bool) – If
True, the final group may contain fewer than n elements. IfFalse, fillvalue will be used to pad the last group if it turns out to be shorter than n. - fillvalue – The item to pad the final chunk with if tail is
Falseand the iterable’s length is not a multiple of n.
Yields: group – An iterable containing the next n or fewer elements of iterable.
Notes
This uses the updated generator protocol as per https://stackoverflow.com/a/45605358/2988730, meaning that this function theoretically requires Python 3.5+.
-
haggis.recipes.immutable(allow_properties=True, docstring='Forbids write access to class attributes.')¶ Create a class decorator that sets a pre-defined version of
__setattr__that forbids write access to the attributes of a class.Access to properties may be allowed through allow_properties. The default setting of
Truedoes not guarantee that properties will be acessible, just that the parent implementation of__setattr__will be responsible for handling the access.The messages of exceptions that are raised are based on the type of access that is requested. They mimic the default message that appear from most Python classes.
Parameters: - allow_properties (bool) – Whether or not to make an exception for properties. If
True, setting of properties will be delegated to the parent’s__setattr__. - docstring (str) – The string to associate with
__setattr__’s __doc__ attibute.
Returns: decorator – A class decorator that inserts a
__setattr__function into the decorated class.Return type: callable
Notes
Checking for properties based on the following Stack Overflow post: https://stackoverflow.com/a/46101204/2988730. See also the discussion following the answer itself.
MRO issues with properly calling
__setattr__on properties are discussed in great detail in the answers and discussion surrounding https://stackoverflow.com/q/46121637/2988730.- allow_properties (bool) – Whether or not to make an exception for properties. If
-
haggis.recipes.islast(iterable)¶ An iterator similar to the builtin
enumerate, except that instead of the index, it returns a boolean flag indicating if the current element is the last one.Based on the recipe at http://stackoverflow.com/a/2429118/2988730. Saw http://stackoverflow.com/a/2429260/2988730 after writing this.
-
haggis.recipes.is_ordered_subset(a, b)¶ Check if iterable a is an ordered subset of iterable b.
An ordered subset means that elements can be selected from b while preserving order in such a way as to get a.
For example,:
0, 1, 2
is an ordered subset of:
0, 2, 1, 3, 2
but:
0, 3, 1
is not.
-
class
haggis.recipes.KeyedSingleton(*args, **kwargs)¶ A meta-class for genralized singleton initialization that returns an existing object based on an input key.
The key is expected to be the first argument to the class constructor.
Inspired by https://stackoverflow.com/a/8665179/2988730 and https://stackoverflow.com/a/31723324/2988730.
I added my own, improved answer at https://stackoverflow.com/a/45175660/2988730
-
__call__(*args, **kwargs)¶ The constructor/initializer require at least one argument since the first argument is the singleton key.
If an instance was already created with the requested key, it is returned without being re-allocated or re-initialized.
-
__init__(*args, **kwargs)¶ Initializes the class with an empty dictionary of instances.
Arguments are name, bases, and attributes, as usual.
-
reset()¶ Resets/clears the class’s registry so that new instances will be constructed for further calls to cls.
-
-
haggis.recipes.lenumerate(iterable, seq_type=None)¶ A generator that returns the length of each element of iterable in addition to the element itself.
Each element must be an iterable itself. seq_type controls the type of sequence the elements will be turned into to get the length. If None, elements are assumed to have a len and will not be altered. Otherwise, seq_type must be a callable that accepts one iterable argument and returns a valid sequence, like
list,tuple,strorbytearray.Specifying seq_type is roughly equivalent to calling
lenumerate(map(seq_type, iterable)). It guarantees consumption of all the elements of the sub-iterables. This could be important for something likegrouper.
-
class
haggis.recipes.RangeBuilder¶ Utility for keeping tracks of the bounds of multiple ranges, e.g., for the limits of a plot.
A new builder is uninitialized at first: start and stop are both None. To add a new range, call the update method. The start and stop properties get the cumulative range.
Any types that support mutual comparison may be supplied to update. Types that support subtraction will enable the span property as well.
-
__init__()¶ Construct a new, uninitialized range builder.
-
init¶ Inidcates whether the range has been initialized or not.
-
range¶ A list containing [start, stop] for a range encompassing all the values encountered so far. None if not initialized.
-
span¶ attribute:: span
For types that support subtraction in addition to comparison, This is the difference between stop and start. None if not initialized.
Type:
-
start¶ The minimum lower bound of any of the ranges encountered so far. None if not initialized with at least one range.
-
stop¶ The maximum upper bound of any of the ranges encountered so far. None if not initialized.
-
update(start, stop=None)¶ Add a range to the builder.
The first call to this method initializes the builder.
Parameters: - start – Any object supporting min comparison against the prior entries.
- stop – Any object supporting max comparison against the prior entries. Optional.
-
-
haggis.recipes.shift_up(*iterables)¶ For a given sequence of iterables, return a sequence of iterables that has all the elements shifted as far left as possible.
In other words, earlier iterables in the sequence are replaced by the next available iterable as they are exhausted.
For example, given:
a = [1] b = [2, 3] c = [4, 5, 6] d = [7, 8]
a, b, c, d = map(list, shift_up(a, b, c, d))will rearrange the lists so that:a = [1, 3, 6] b = [2, 5] c = [4, 8] d = [7]
The result is a list of lists.
string_util module¶
Utilities for creating, chopping, concatenating and otherwise processing strings.
The functions in this module that operate on multi-line strings have
versions that start with split_, which accept iterables of lines
instead of entire strings.
-
haggis.string_util.hasspace(x)¶ Check if string x contains a space.
If x is not a string, and is not Falsy, it is coerced into a string. Falsy inputs never have spaces (according to this function).
-
haggis.string_util.func_name(obj)¶ Retrieves the qualified function name of an object.
The following rules are implemented: 1. If the object is None, return None 2. If the object has a __qualname__ attribute, return it 3. If the object has a __name__ attribute, return it 4. Return the
reprof the object
-
haggis.string_util.format_list(iterable, width=8, format=None, sep=', ', indent=None)¶ Display the elements of the iterable, width elements per line.
Parameters: - iterable (iterable) – The iterable to pretty-print.
- width (int) – The number of elements to print per line. Defaults to 8. If
None, the entire list will appear on one line. - format (str) – A new-style format string to represent each value. Defaults to
'{}'. - sep (str) – The separator to place between entries on the same line.
Defaults to
', '. - indent (int or str) – If
int, the number of spaces by which to indent each line of the input. If astr, act as a literal prefix to each line. Defaults to4unlesswidthisNone, in which case the default is an empty string.
Returns: formatted_data – A string containing the formatted data.
Return type:
-
class
haggis.string_util.parse_pair(sep='-', trim=None, item_type=None, output_type=None)¶ Configure a parser for delimited pairs of items.
Pairs get special treatment because they are a ubiquitous type that can be used to implement, among other things, ranges.
-
classmethod
inclusive_range(sep='-', trim=None, output_type=<class 'range'>)¶ Create a parser for ranges of :py:type:`int` objects into a :py:type:`range` (or compatible type).
To parse a slice with no step, use
sep=':'andoutput_type=slice.Parameters are the same as for the class, except that item_type is fixed.
-
classmethod
-
class
haggis.string_util.parse_list(sep=', ', trim=None, item_types=None)¶ Configure a parser for delimited lists of items.
Lists can contain items of different types, which are determined by sequentially applying a list of sub-parsers.
-
classmethod
number_list(sep=', ', range_sep='-', trim=None)¶ Create a parser for a list of :py:type:`int` objects that also supports ranges.
Parameters are the same as for the class, except that item_type is fixed and range_sep is the sep parameter of
parse_pair. trim is passed as well.
-
classmethod
-
haggis.string_util.align(string, *args, **kwargs)¶ Align a string in a space-padded field of the specified width.
This function differs from just doing something like
{0:{1}{2}}.format(string, alignment, width)
because the “actual” length of the string is computed by len_key rather than the builtin
len. It also correctly handles multiline strings.Parameters: - string (str) – The string to align. May contain multiple lines.
- alignment (str or None) –
A value that indicates how to align lines. Recognized options are as follows:
'left'or'<'- string is padded on the right to width.
'center'or'^'- string is padded equally on each side to width.
'right'or'>'- string is padded on the left to width.
'none',''orNone- string is returned as-is, regardless of width.
- width (int or None) – The minimum field width to align in. If
None, use the maximum line length as the field width.Nonedoes not make much sense for a single-line string: it will just be returned as-is. If width is shorter than any of the lines, it will have no effect. - overflow (str or callable) –
How to handle overflow lines (wider than width). The following options are accepted:
'extend'- The effective width will be the largest of the maximum line length and width. This is the default.
skip- Skip longer lines, but align shorter ones to width.
'trunc'- Truncate to width. This may not work correctly if
len_key is not the builtin function
len. Use the callable option in that case. callable- A function that accepts long input lines and returns a
truncated line. This can do special truncation or any other
operation the user desires. The result will be aligned using
overflow=skipin this case. The callable will only be applied to overflow lines.
This parameter is completely ignored if width is
None. - len_key (callable) – A custom callable for computing the lengths of strings. This can
be useful for example if the strings contain tabs or some
similar sequence whose display width is not necessarily the raw
string width. Defaults to the builtin
len.
Returns: aligned – string aligned in a field of size width according to the spec. If the input string is greater than or equal to width in length, it is returned as-is.
Return type:
-
haggis.string_util.split_align(strings, alignment, width=None, overflow='extend', len_key=<built-in function len>)¶ Identical to
alignexcept that the lines are passed in as an iterable instead of a single string.The result is a list of lines rather than a single string.
-
haggis.string_util.horiz_cat(*strings, **kwargs)¶ Concatenate multi-line strings side-by-side.
For single line strings, this function is equivalent to
prefix + sep.join(*strings) + suffix.Parameters: - *strings (str) – Any number of strings. This function is pointless if none of the strings have more than one line, but multiple lines are not a requirement.
- prefix (str) – A prefix that will be prepended to each line of the result. This can be used to do indentation, among other things. Default is empty.
- sep (str) – The separator to insert between columns. The separator will be
omitted around empty columns if
missing='missing'. Default is a single space. - suffix (str) – A suffix that will be added to each line in the result. Default is empty.
- linesep (str) – The line separator to use. The default is
os.linesep. - alignment (str, sequence[str] or None) –
A value that indicates how to align strings. Acceptable values are as follows:
'left'or'<'- Each string is padded on the right to the length of the maximum line length. Shorter lines are left aligned.
'center'or'^'- Each string is padded equally on each side to the length of the maximum line length. Shorter lines are center aligned.
'right'or'>'- Each string is padded on the left to the length of the maximum line length. Shorter lines are right aligned.
'none',''orNone- Strings are not padded at all, just concatenated as-is.
If a sequence if passed in, it must contain as many elements as strings. Each column in strings will be aligned according to the corresponding alignment. Having
'none'elements is not strictly forbidden in this case, but it may completely throw off the formatting of the following columns.The default is
'<'. - missing (str or int) –
A specification for how to handle strings with fewer lines than the others. This does not apply to empty lines within the string. Acceptable values are as follows:
'down'- Shift all shorter inputs down using empty lines.
'trunc'- Truncate all inputs to the smallest number of lines.
'empty'- The default is to treat missing lines as through they are empty lines. All alignement rules apply.
'last'- Repeat the last line.
'first'- Repeat the first line. A synonym for
missing=0. - int or string that evaluates to int
- Repeat the n-th line. Use this carefully as it will raise an
error if any of the strings have fewer than
n+1lines.
The default is
'empty'. - len_key (callable) – A custom callable for computing the lengths of strings. This can
be useful for example if the strings contain tabs or some
similar sequence whose display width is not necessarily the raw
string width. Defaults to the builtin
len. - titles (sequence[str] or None) – If provided, a list of column titles for each column. titles can appear with or without headers, which provides the underline. Titles behave as a normal line in strings. Multiline titles are supported.
- headers (str or callable or sequence[str or callable] or None) –
Text that separates titles from strings. There are two options available:
- string
- Aligned the same way as each column in strings
- callable
- Called with the column width as a single argument, the
return value is the column header. A common option include
c.__mul__for a single repeated characterc.
Columns are separated by hsep instead of sep. Multiline headers are not supported, though not technically an error.
- hsep (str or None) – If headers is used, column separator for the header row. titles uses sep. The length of hsep must be the same as that of sep if headers is used. If not set, defaults to sep when headers is used. Ignored if headers is not set.
- width (int or sequence[int] or None) – The minimum width for each column, or across all columns. If not set, the actual column width will be used.
Returns: cat – A string that is a side-by-side concatenation of the inputs given the selected options.
Return type: Raises: ValueError– If alignment or missing are set to invalid values. Also if sep and hsep are both used and do not match in size with non-None alignment.IndexError– If missing is an integer or a string that parses as an integer but one of the input strings does not contain the specified line index. Or if any of alignment, titles, headers, minwidth are sequences that are of different length than strings.
-
haggis.string_util.split_horiz_cat(*columns, prefix='', sep=' ', suffix='', linesep='\n', alignment='<', missing='empty', len_key=<built-in function len>, titles=None, headers=None, hsep=None, width=None)¶ Identical to
horiz_cat, except the inputs are sequences of strings already split into lines.If linesep is
None, the output will not be combined into a string, but will be returned as alistinstead.
-
haggis.string_util.make_box(string, style='ascii-block', alignment='^', linesep='\n', horizontal_padding=1, vertical_padding=0, len_key=<built-in function len>)¶ Surrounded the input string by a box.
Parameters: - string (str) – A string, which may contain multiple lines.
- style (str) –
The type of box to draw. Styles are registered with
register_box_style. Predefined styles are'ascii-block''ascii-line''shaded''block''half-block''half-block-inner''line''bold-line''rounded-line''double-line'
All but the
'ascii-*'styles use unicode characters. The default is'ascii-block'. - alignment (str or None) –
A value that indicates how to align lines in multiline strings. Acceptable values are as follows:
'left'or'<'- Each string is padded on the right to the length of the maximum line length. Shorter lines are left aligned.
'center'or'^'- Each string is padded equally on each side to the length of the maximum line length. Shorter lines are center aligned.
'right'or'>'- Each string is padded on the left to the length of the maximum line length. Shorter lines are right aligned.
Default is
'^'. - linesep (str) – The line separator to use. The default is
os.linesep. - horizontal_padding (int) – The number of spaces to place between the string and the left and right borders. Defaults to one space on each side.
- vertical_padding (int) – The number of newlines to place between the string and the top and bottom border. Defaults to one line on each side.
- len_key (callable) – A custom callable for computing the lengths of strings. This can
be useful for example if the strings contain tabs or some
similar sequence whose display width is not necessarily the raw
string width. Defaults to the builtin
len.
Returns: box – The input string surrounded by a border box. The return value will always be a multi-line string.
Return type:
-
haggis.string_util.register_box_style(name, top, left, bottom, right, ul, ur, bl, br)¶ Create a new box style that is available to
make_boxthrough name.A style is defined by specifying the characters to use for each side and corner of the box. Normally, borders are specified as a single character, but this is not required.
Registering an existing style will silently overwrite the previous style.
Parameters: - name (str) – The name by which the style will be accessible to
make_boxvia the style parameter. - top (str) – The character or characters to use for the top side of the box.
- left (str) – The character or characters to use for the left side of the box.
- bottom (str) – The character or characters to use for the bottom side of the box.
- right (str) – The character or characters to use for the right side of the box.
- ul (str) – The character or characters that will join top and left borders in the upper left-hand corner.
- ur (str) – The character or characters that will join top and right borders in the upper right-hand corner.
- bl (str) – The character or characters that will join bottom and left borders in the lower left-hand corner.
- br (str) – The character or characters that will join bottom and right borders in the lower right-hand corner.
The elements of the left column of the box will be right-aligned based on the longest among ul, left and bl. The elements of the right side will be similarly left-aligned based on the longest among ur, right and br.
Style string elements may contain multiple lines. In that case, all the lines will be left-aligned.
- name (str) – The name by which the style will be accessible to
-
haggis.string_util.check_value(string, options, insensitive=True, label='option')¶ Verifiy that string is within the allowed options.
Raise a
ValueErrorif not found.Parameters: - string (str) – The string to verify.
- options (mapping[str, str] or iterable[str]) – A container that supports the
inoperator. If the container is a mapping that can be indexed by the input, the result is the “normalized” version of the string that will be returned. - insensitive (bool) – Whether or not to do a case insensitive comparison (using
str.casefold). IfTrue, options is expected to contain casefolded items. - label (str) – The label used to describe string if it is not found in options.
Returns: check – The input string if it is in options. If options is a mapping, the result will be
options[string]instead. This allows normalization of the input so that multiple input options can represent the same output value.Return type:
-
haggis.string_util.to_casefold(string, conv=<class 'str'>)¶ Convert the input to a string and casefold it.
Conversion is done by conv, which is normally
str, butrepris sometimes a good choice as well.
-
haggis.string_util.to_lower(string, conv=<class 'str'>)¶ Convert the input to a string and lowercase it.
Conversion is done by conv, which is normally
str, butrepris sometimes a good choice as well.
-
haggis.string_util.to_upper(string, conv=<class 'str'>)¶ Convert the input to a string and uppercase it.
Conversion is done by conv, which is normally
str, butrepris sometimes a good choice as well.
-
haggis.string_util.to_hex(b, prefix='', sep='')¶ Convert a string of bytes to a hex string.
Parameters: Returns: A string consisting of the characters 0-9, A-Z (as well as prefix and sep), with two digits per byte of input.
Return type:
-
haggis.string_util.camel2snake(string)¶ Convert a string to snake_case, assuming input in CamelCase.
Parameters: string (str) – The string to convert. Returns: A string similar to the input, but any uppercase letters are lowercased and an underscore is prepended, unless there is one there already. Return type: str
-
haggis.string_util.snake2camel(string, first_upper=False)¶ Convert a string to CamelCase, assuming input in snake_case.
Parameters: Returns: A string similar to the input, but any underscores removed, and the following letters uppercased.
Return type:
-
haggis.string_util.multiline_repr(args=(), kws=())¶ Decorator providing a “fancy” version of __repr__ to classes.
The version of __repr__ prints the type name, with an argument list determined by repr_args and repr_kws. The argument lists are stored in class properties named _multiline_repr_args and _multiline_repr_kws. These aggregate across inheritance trees.
Setting either iterable explicitly to None instead of an empty iterable will dynamically use list(vars(self)).
Parameters: - args (Iterable) – An iterable of strings or 2-element tuples (may be mixed). Tuples are of the form (keyword, function). function must have a signature like getattr. If keyword starts with an asterisk (*), the function is expected to return an iterable of individual arguments, otherwise it returns a single argument.
- kws (Iterable) – An iterable of the same type as args, except that star-arguments are forbidden: each keyword may only refer to a single object.
Returns: - A decorator that will add a __repr__ method and two properties
- to a class. The result of __repr__ will be the class name and a
- pretty-printed argument list, displayed across multiple lines.
Examples
Indentation works with nested multiline representations:
>>> @multiline_repr('p', 'q') ... class Inner: ... def __init__(self, p, q=None): ... self.p = p ... self.q = q >>> @multiline_repr(['a', 'b'], ['x', ('y', lambda obj, attr: obj.z)]) ... class Test: ... def __init__(self): ... self.a = 1 ... self.b = 2 ... self.x = Inner('a', 'b') ... self.z = 'omega' ... >>> print(Test()) Test(1, 2, x=Inner('a', q='b'), y='omega')
And with inheritance:
>>> @multiline_repr(['r', ('*s', lambda obj, attr: ('cat', 'dog'))], ['t']) ... class Outer(Inner): ... def __init__(self): ... super().__init__('start') ... self.r = 'stop' ... self.t = 'none' >>> print(Outer()) Outer('start', 'stop', 'cat', 'dog', q=None, t='none')
structures module¶
Pure-python implementation of some useful data structures.
-
class
haggis.structures.Trie(empty=None, sorter=None, joiner=None)¶ Simple general purpose Trie implementation with methods for adding, removing, checking containment, and iterating.
Root can be a leaf if the empty string is a prefix. Keys must be hashable.
-
__contains__(item)¶ Check if the specified item, represented as an iterable of parts, is a leaf of this trie.
Parameters: item – An iterable of keys. The last element is checked for leafness. An empty iterable refers to the root node. Returns: True if a the last element of item represents a leaf in the trie, False otherwise, even if it is a valid node. Return type: bool
-
__init__(empty=None, sorter=None, joiner=None)¶ Make an empty trie.
Do not delete existing data (e.g. if invoked multiple times).
Parameters: - empty (optional) – The key of the root node, associated with an empty trie. The default is None.
- sorter (callable, optional) – A callable that determines the sort order of suffixes
during default iteration. If provided, must accept a list
of keys and return an iterable. May filter the input by
returning a subset. May be None (the default) to indicate
no sorting on iteration. See
iterfor more information. - joiner (callable, optional) – A callable that determines the concatenation of nodes
during default iteration. If provided, must accept an
iterable of keys and return the concatenated object. May
be None (the default) to indicate no concatenation. See
iterfor more information.
-
__iter__()¶ Default iterator over the leaf sequences.
Iteration happens in deapth-first order. A customizable iterator is available through the
itermethod.
-
__len__()¶ Length is the number of leaf nodes, consistent with iteration.
Returns: The number of leaves in this trie. Return type: int
-
__repr__()¶ String representation of this trie.
Returns: A multi-line description, with nodes indented to show hierarchy. Return type: str
-
add(item)¶ Add an item, represented as an iterable of parts.
The last element of the iterable is marked as a leaf.
Parameters: item – An iterable of keys. The last element will be marked as a leaf. An empty iterable refers to the root node. Returns: True if a new leaf is added (even if it is prefix to an existing suffix), False if already a leaf. Return type: bool
-
iter(sorter=None, joiner=None, dfs=True)¶ Custom iterator over leaves of the trie.
Parameters: - sorter (callable or None) – If provided, used to sort the suffixes for each node. Otherwise, leaves will appear in insertion order (or none at all pre-Python 3.6). sorter must be a callable that accepts a list of keys and returns an iterable of keys. It can be used to filter elements as well as sort them.
- joiner (callable) – If provided, used to concatenate all the elements of each leaf. Otherwise, yield tuples with the elements. joiner must be a callable that accepts an iterable of keys and returns the concatenated object. The first element will always be the empty root key.
- dfs (bool) – Whether to perform breadth-first or depth-first-search. If dfs is False, a breadth-first order will be used rather than depth-first.
-
remove(item)¶ Remove an item, represented as an iterable of parts.
If the leaf has a suffix, it is simply unmarked. If not, it, and its parents will be removed until a node with a different suffix or that is a leaf is encountered.
Parameters: item – An iterable of keys. The last element will no longer be a leaf and may be deleted. An empty iterable refers to the root node. Returns: True if the item was found and a node was removed, False if it did not represent a valid leaf. Return type: bool
-
classmethod
string_paths(sorter=<built-in function sorted>, joiner=None)¶ Create a trie for paths.
Able to handle relative and absolute paths fairly well in the same trie,
Parameters: - sorter (callable, optional) – A replacement sorter. The default is
sorted, which implies case sensitivity. - joiner (callable, optional) – A replacement joiner. The default joiner handles concatenation with the correct path separator, and proper identification of absolute and relative paths.
Returns: A trie for paths.
Return type: - sorter (callable, optional) – A replacement sorter. The default is
-
threads module¶
Tools to help with threading.
-
class
haggis.threads.Heartbeat(emit, name='heartbeat', interval=1.0)¶ A simple timer-like thread that emits a signal at fixed intervals.
The thread can be stopped and paused using a context manager.
-
__init__(emit, name='heartbeat', interval=1.0)¶ Construct a thread with the specified signal, name and interval.
Parameters:
-
run()¶ Emit a signal immediately, and at somewhat regular intervals thereafter.
-
start()¶ Start the thread.
-
stop()¶ Stop the heartbeat.
The thread may not die until the current interval completes, but the signal will not be emitted again once this method is called.
-
suspend()¶ Context manager to temporarily suspend the heartbeat.
Emission will stop when the manager enters, and resume on the next interval when it exits. Thread will die if an error occurs during suspension. Intervals are still timed while the thread is suspened.
-
time module¶
Timing, timer, time and suchlike tools.
-
class
haggis.time.Stopwatch(start=None)¶ Rough lightweight timer context manager.
This is not intended to be used for precise benchmarking, but can give a good idea of how long operations in a with block take.
The context manager can be reused as many times as necessary. When first created, it reports time relative to its creation time, unless specifically requested otherwise.
-
start¶ The start time of the stopwatch, as a floating point timestamp from Epoch (see
time.time). This is valid regardless of whether the stopwatch is running or not.
-
end¶ The end time of the stopwatch, as a floating point timestamp from Epoch (see
time.time). If the stopwatch is running, this is set to None. If it is stopped or paused, this attribute records the time of the stop or pause.
-
pauses¶ A sequence containing
(start, end)tuples for every pause triggered since the last restart. The last element may be a placeholder object if the stopwatch is paused. All tuple elements have units of seconds from Epoch (seetime.time).
-
pause_duration¶ The sum of the durations of all the pauses, in seconds.
This class is not thread safe.
-
__init__(start=None)¶ Create a new stopwatch, starting from now.
Parameters: start (float or None, optional) – The start timestamp, or now if None. The default is None.
-
__str__()¶ Pretty-prints the duration of this stopwatch, with a label to indicate if it is running.
Returns: A string representation of the stopwatch duration. Return type: str
-
clear()¶ Removes all pause records, including any current ones.
Clearing the records will affect the reported duration, whether the stopwatch is running or not.
-
duration¶ The duration of the stopwatch timer, including any intervening pauses. If the stopwatch is running, this is the duration until now. If stopped, this is the duration between start and stop.
-
pause()¶ Pause the stopwatch, if not already paused.
This method returns a context manager. Entering the context manager does nothing, but exiting it unpauses this timer.
Calling this method multiple times without unpausing will lead to potentially unexpected behavior. All context managers returned by this method unpause the stopwatch. That means, for example, that nesting context managed calls to
pausewill unpause when the innermost context manager exits, not the outermost.Returns: - A subsidiary context manager that can be used to automatically
unpausewhen it exits.
-
restart()¶ Clears the pause sequence and restarts the timer.
-
stop()¶ Stops the timer.
Calling this method multiple times will update
endandpause_duration, and append a new entry to thepausessequence from the last stop/pause.
-
unpause()¶ Unpause the timer, if it has been paused.
pause_durationis updated and a new entry is appended topausesif the timer was not running.
-
-
haggis.time.timestamp(t=None)¶ Return the current or other date and time in the format
YYYYMMDD_HHMMSS.Parameters: t (datetime.datetime or None) – The date to format. If None, use the result of datetime.datetime.now.Returns: The formatted date. Return type: str